 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the value of information transfer in population-based SHM
Nov 06, 2023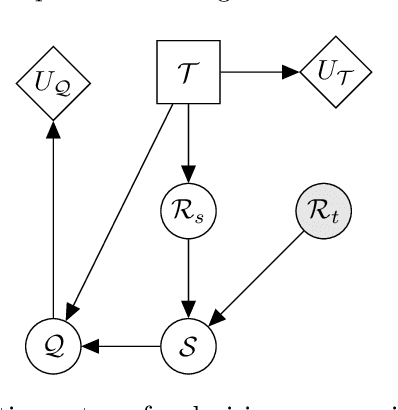

Population-based structural health monitoring (PBSHM), seeks to address some of the limitations associated with data scarcity that arise in traditional SHM. A tenet of the population-based approach to SHM is that information can be shared between sufficiently-similar structures in order to improve predictive models. Transfer learning techniques, such as domain adaptation, have been shown to be a highly-useful technology for sharing information between structures when developing statistical classifiers for PBSHM. Nonetheless, transfer-learning techniques are not without their pitfalls. In some circumstances, for example if the data distributions associated with the structures within a population are dissimilar, applying transfer-learning methods can be detrimental to classification performance -- this phenomenon is known as negative transfer. Given the potentially-severe consequences of negative transfer, it is prudent for engineers to ask the question `when, what, and how should one transfer between structures?'. The current paper aims to demonstrate a transfer-strategy decision process for a classification task for a population of simulated structures in the context of a representative SHM maintenance problem, supported by domain adaptation. The transfer decision framework is based upon the concept of expected value of information transfer. In order to compute the expected value of information transfer, predictions must be made regarding the classification (and decision performance) in the target domain following information transfer. In order to forecast the outcome of transfers, a probabilistic regression is used here to predict classification performance from a proxy for structural similarity based on the modal assurance criterion.
A decision framework for selecting information-transfer strategies in population-based SHM
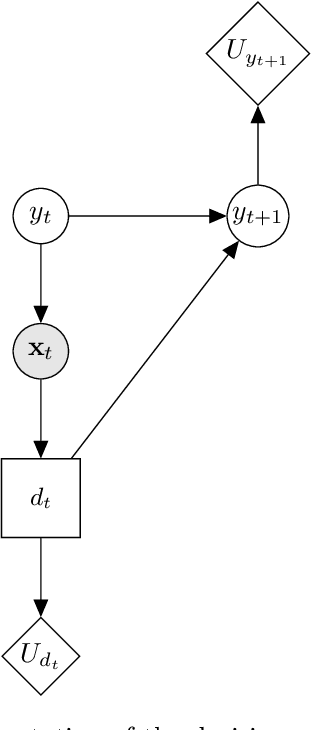
Jul 13, 2023Decision-support for the operation and maintenance of structures provides significant motivation for the development and implementation of structural health monitoring (SHM) systems. Unfortunately, the limited availability of labelled training data hinders the development of the statistical models on which these decision-support systems rely. Population-based SHM seeks to mitigate the impact of data scarcity by using transfer learning techniques to share information between individual structures within a population. The current paper proposes a decision framework for selecting transfer strategies based upon a novel concept -- the expected value of information transfer -- such that negative transfer is avoided. By avoiding negative transfer, and by optimising information transfer strategies using the transfer-decision framework, one can reduce the costs associated with operating and maintaining structures, and improve safety.
Towards risk-informed PBSHM: Populations as hierarchical systems
Mar 13, 2023The prospect of informed and optimal decision-making regarding the operation and maintenance (O&M) of structures provides impetus to the development of structural health monitoring (SHM) systems. A probabilistic risk-based framework for decision-making has already been proposed. However, in order to learn the statistical models necessary for decision-making, measured data from the structure of interest are required. Unfortunately, these data are seldom available across the range of environmental and operational conditions necessary to ensure good generalisation of the model. Recently, technologies have been developed that overcome this challenge, by extending SHM to populations of structures, such that valuable knowledge may be transferred between instances of structures that are sufficiently similar. This new approach is termed population-based structural heath monitoring (PBSHM). The current paper presents a formal representation of populations of structures, such that risk-based decision processes may be specified within them. The population-based representation is an extension to the hierarchical representation of a structure used within the probabilistic risk-based decision framework to define fault trees. The result is a series, consisting of systems of systems ranging from the individual component level up to an inventory of heterogeneous populations. The current paper considers an inventory of wind farms as a motivating example and highlights the inferences and decisions that can be made within the hierarchical representation.
Mitigating sampling bias in risk-based active learning via an EM algorithm
Jun 25, 2022

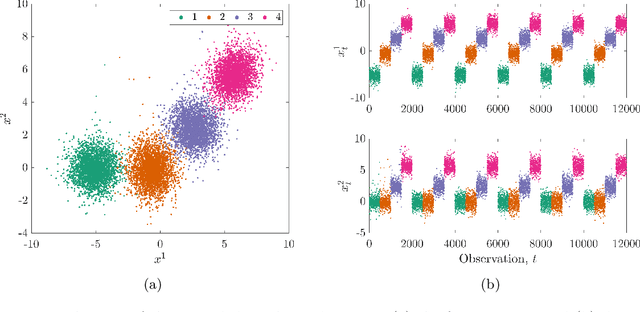
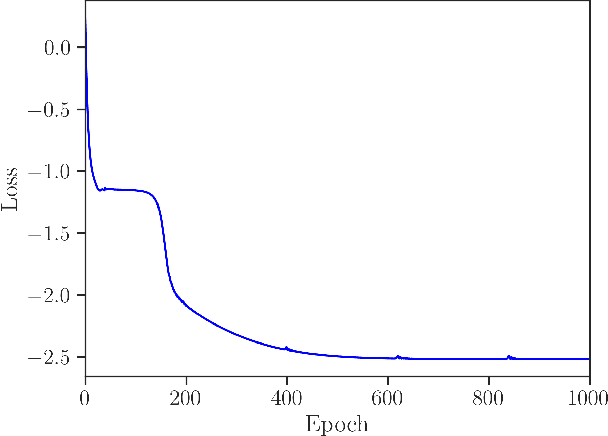
Risk-based active learning is an approach to developing statistical classifiers for online decision-support. In this approach, data-label querying is guided according to the expected value of perfect information for incipient data points. For SHM applications, the value of information is evaluated with respect to a maintenance decision process, and the data-label querying corresponds to the inspection of a structure to determine its health state. Sampling bias is a known issue within active-learning paradigms; this occurs when an active learning process over- or undersamples specific regions of a feature-space, thereby resulting in a training set that is not representative of the underlying distribution. This bias ultimately degrades decision-making performance, and as a consequence, results in unnecessary costs incurred. The current paper outlines a risk-based approach to active learning that utilises a semi-supervised Gaussian mixture model. The semi-supervised approach counteracts sampling bias by incorporating pseudo-labels for unlabelled data via an EM algorithm. The approach is demonstrated on a numerical example representative of the decision processes found in SHM.
Improving decision-making via risk-based active learning: Probabilistic discriminative classifiers
Jun 23, 2022
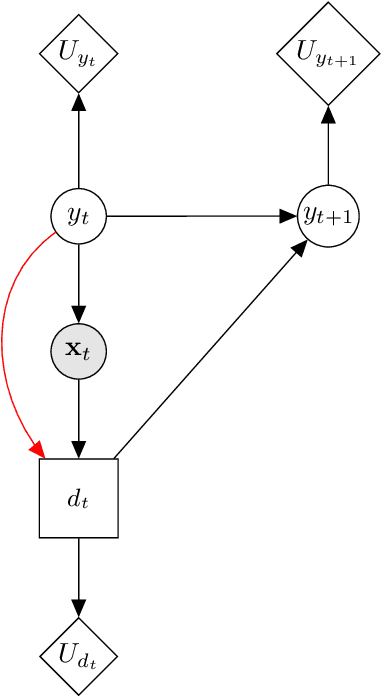
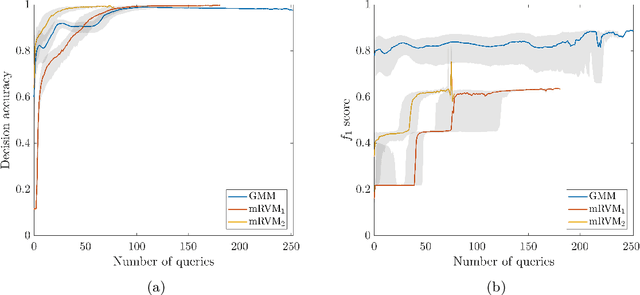
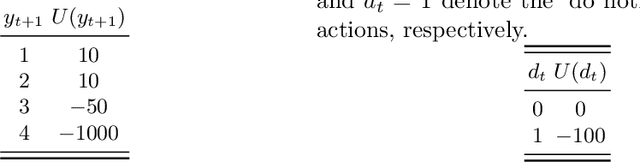
Gaining the ability to make informed decisions on operation and maintenance of structures provides motivation for the implementation of structural health monitoring (SHM) systems. However, descriptive labels for measured data corresponding to health-states of the monitored system are often unavailable. This issue limits the applicability of fully-supervised machine learning paradigms for the development of statistical classifiers to be used in decision-support in SHM systems. One approach to dealing with this problem is risk-based active learning. In such an approach, data-label querying is guided according to the expected value of perfect information for incipient data points. For risk-based active learning in SHM, the value of information is evaluated with respect to a maintenance decision process, and the data-label querying corresponds to the inspection of a structure to determine its health state. In the context of SHM, risk-based active learning has only been considered for generative classifiers. The current paper demonstrates several advantages of using an alternative type of classifier -- discriminative models. Using the Z24 Bridge dataset as a case study, it is shown that discriminative classifiers have benefits, in the context of SHM decision-support, including improved robustness to sampling bias, and reduced expenditure on structural inspections.
On statistic alignment for domain adaptation in structural health monitoring
May 24, 2022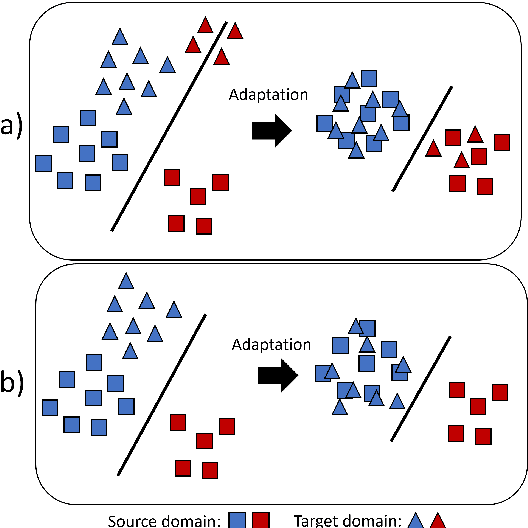
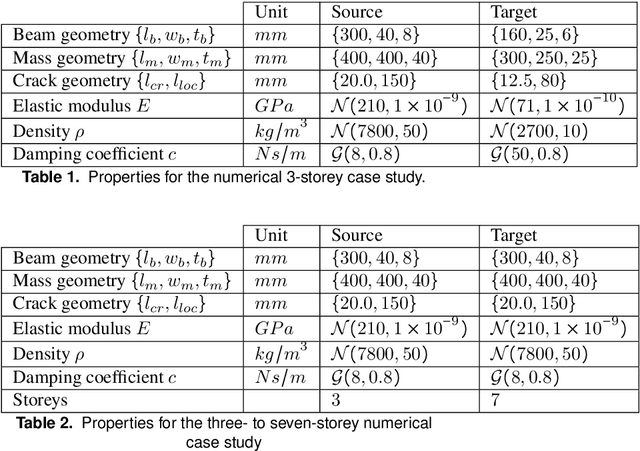
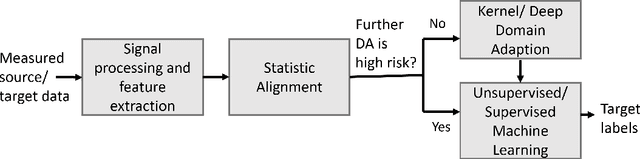
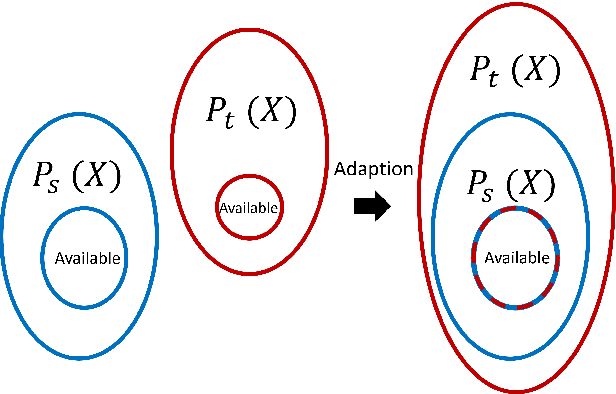
The practical application of structural health monitoring (SHM) is often limited by the availability of labelled data. Transfer learning - specifically in the form of domain adaptation (DA) - gives rise to the possibility of leveraging information from a population of physical or numerical structures, by inferring a mapping that aligns the feature spaces. Typical DA methods rely on nonparametric distance metrics, which require sufficient data to perform density estimation. In addition, these methods can be prone to performance degradation under class imbalance. To address these issues, statistic alignment (SA) is discussed, with a demonstration of how these methods can be made robust to class imbalance, including a special case of class imbalance called a partial DA scenario. SA is demonstrated to facilitate damage localisation with no target labels in a numerical case study, outperforming other state-of-the-art DA methods. It is then shown to be capable of aligning the feature spaces of a real heterogeneous population, the Z24 and KW51 bridges, with only 220 samples used from the KW51 bridge. Finally, in scenarios where more complex mappings are required for knowledge transfer, SA is shown to be a vital pre-processing tool, increasing the performance of established DA methods.
On robust risk-based active-learning algorithms for enhanced decision support
Jan 07, 2022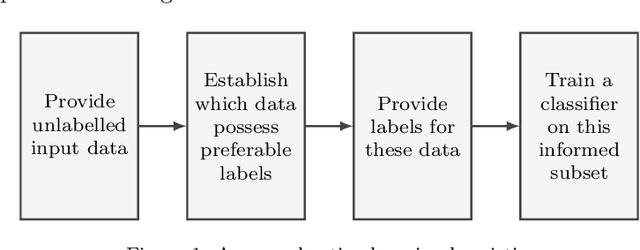
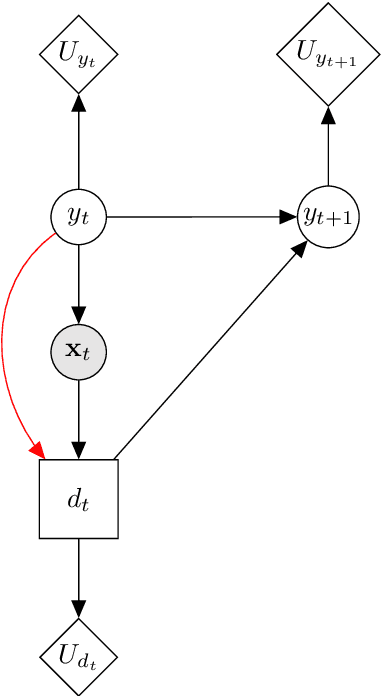
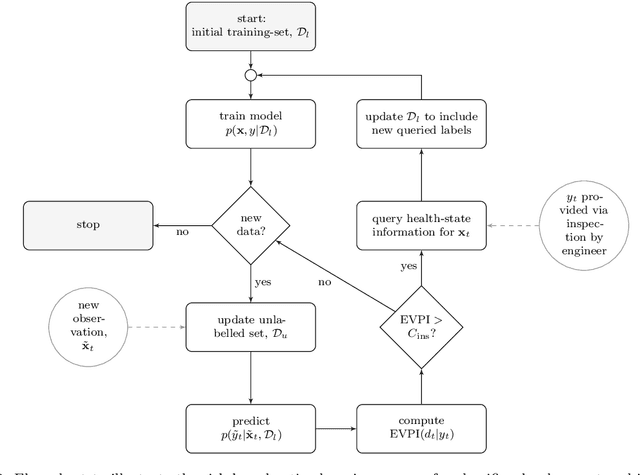
Classification models are a fundamental component of physical-asset management technologies such as structural health monitoring (SHM) systems and digital twins. Previous work introduced \textit{risk-based active learning}, an online approach for the development of statistical classifiers that takes into account the decision-support context in which they are applied. Decision-making is considered by preferentially querying data labels according to \textit{expected value of perfect information} (EVPI). Although several benefits are gained by adopting a risk-based active learning approach, including improved decision-making performance, the algorithms suffer from issues relating to sampling bias as a result of the guided querying process. This sampling bias ultimately manifests as a decline in decision-making performance during the later stages of active learning, which in turn corresponds to lost resource/utility. The current paper proposes two novel approaches to counteract the effects of sampling bias: \textit{semi-supervised learning}, and \textit{discriminative classification models}. These approaches are first visualised using a synthetic dataset, then subsequently applied to an experimental case study, specifically, the Z24 Bridge dataset. The semi-supervised learning approach is shown to have variable performance; with robustness to sampling bias dependent on the suitability of the generative distributions selected for the model with respect to each dataset. In contrast, the discriminative classifiers are shown to have excellent robustness to the effects of sampling bias. Moreover, it was found that the number of inspections made during a monitoring campaign, and therefore resource expenditure, could be reduced with the careful selection of the statistical classifiers used within a decision-supporting monitoring system.
Probabilistic Inference for Structural Health Monitoring: New Modes of Learning from Data
Mar 02, 2021
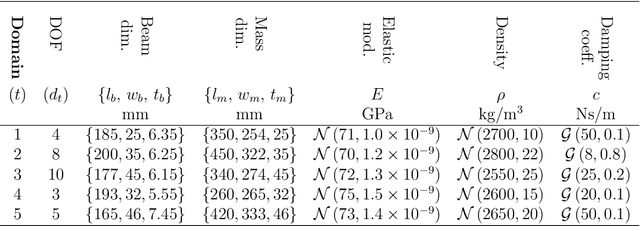
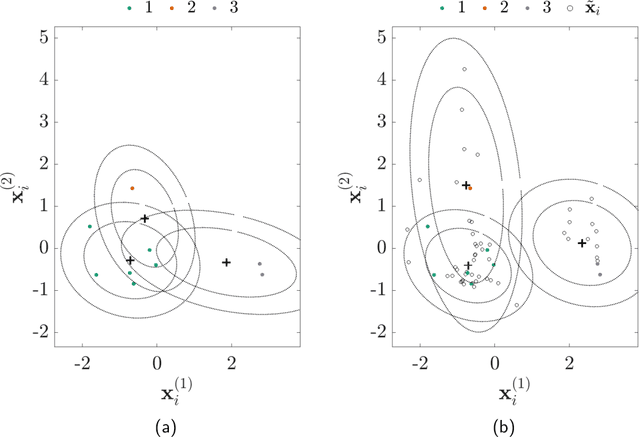
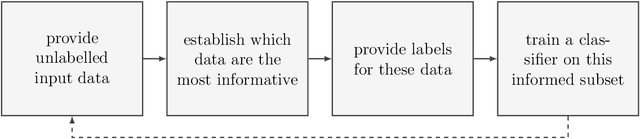
In data-driven SHM, the signals recorded from systems in operation can be noisy and incomplete. Data corresponding to each of the operational, environmental, and damage states are rarely available a priori; furthermore, labelling to describe the measurements is often unavailable. In consequence, the algorithms used to implement SHM should be robust and adaptive, while accommodating for missing information in the training-data -- such that new information can be included if it becomes available. By reviewing novel techniques for statistical learning (introduced in previous work), it is argued that probabilistic algorithms offer a natural solution to the modelling of SHM data in practice. In three case-studies, probabilistic methods are adapted for applications to SHM signals -- including semi-supervised learning, active learning, and multi-task learning.
* This material may be downloaded for personal use only. Any other use requires prior permission of the American Society of Civil Engineers. This material may be found at https://doi.org/10.1061/AJRUA6.0001106