 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the value of positive transfer: An experimental case study
Jul 19, 2024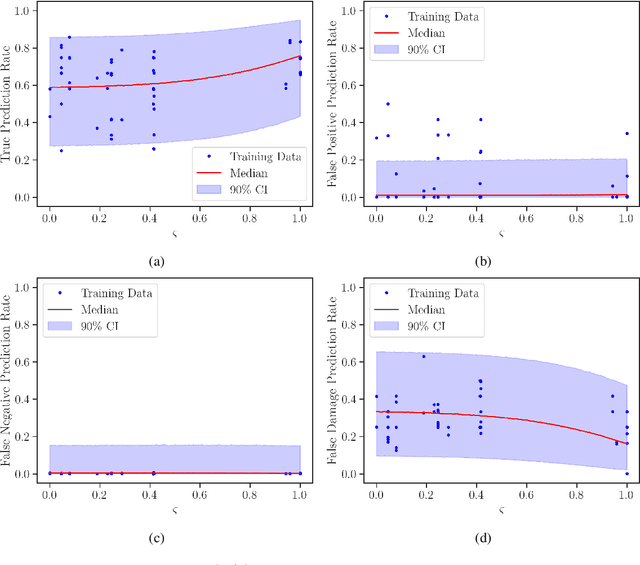

In traditional approaches to structural health monitoring, challenges often arise associated with the availability of labelled data. Population-based structural health monitoring seeks to overcomes these challenges by leveraging data/information from similar structures via technologies such as transfer learning. The current paper demonstrate a methodology for quantifying the value of information transfer in the context of operation and maintenance decision-making. This demonstration, based on a population of laboratory-scale aircraft models, highlights the steps required to evaluate the expected value of information transfer including similarity assessment and prediction of transfer efficacy. Once evaluated for a given population, the value of information transfer can be used to optimise transfer-learning strategies for newly-acquired target domains.
Quantifying the value of information transfer in population-based SHM
Nov 06, 2023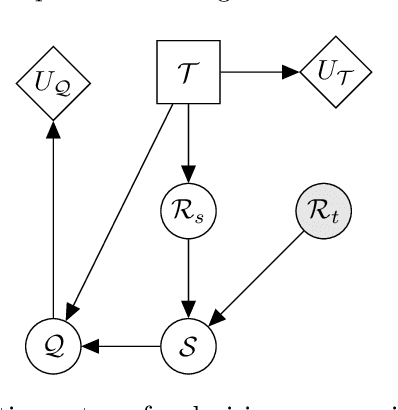

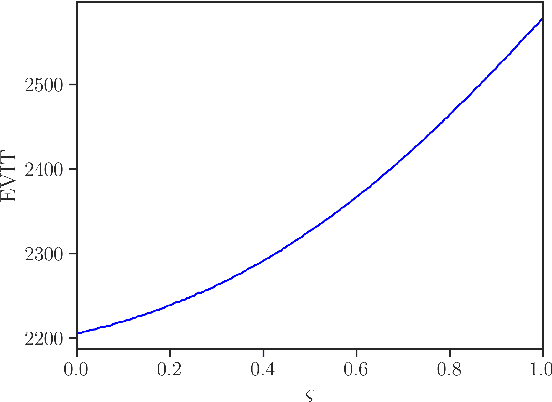
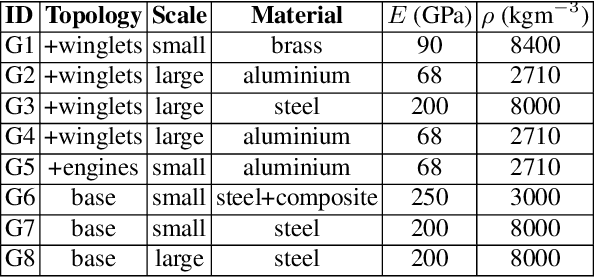
Population-based structural health monitoring (PBSHM), seeks to address some of the limitations associated with data scarcity that arise in traditional SHM. A tenet of the population-based approach to SHM is that information can be shared between sufficiently-similar structures in order to improve predictive models. Transfer learning techniques, such as domain adaptation, have been shown to be a highly-useful technology for sharing information between structures when developing statistical classifiers for PBSHM. Nonetheless, transfer-learning techniques are not without their pitfalls. In some circumstances, for example if the data distributions associated with the structures within a population are dissimilar, applying transfer-learning methods can be detrimental to classification performance -- this phenomenon is known as negative transfer. Given the potentially-severe consequences of negative transfer, it is prudent for engineers to ask the question `when, what, and how should one transfer between structures?'. The current paper aims to demonstrate a transfer-strategy decision process for a classification task for a population of simulated structures in the context of a representative SHM maintenance problem, supported by domain adaptation. The transfer decision framework is based upon the concept of expected value of information transfer. In order to compute the expected value of information transfer, predictions must be made regarding the classification (and decision performance) in the target domain following information transfer. In order to forecast the outcome of transfers, a probabilistic regression is used here to predict classification performance from a proxy for structural similarity based on the modal assurance criterion.
A decision framework for selecting information-transfer strategies in population-based SHM
Jul 13, 2023Decision-support for the operation and maintenance of structures provides significant motivation for the development and implementation of structural health monitoring (SHM) systems. Unfortunately, the limited availability of labelled training data hinders the development of the statistical models on which these decision-support systems rely. Population-based SHM seeks to mitigate the impact of data scarcity by using transfer learning techniques to share information between individual structures within a population. The current paper proposes a decision framework for selecting transfer strategies based upon a novel concept -- the expected value of information transfer -- such that negative transfer is avoided. By avoiding negative transfer, and by optimising information transfer strategies using the transfer-decision framework, one can reduce the costs associated with operating and maintaining structures, and improve safety.
On statistic alignment for domain adaptation in structural health monitoring
May 24, 2022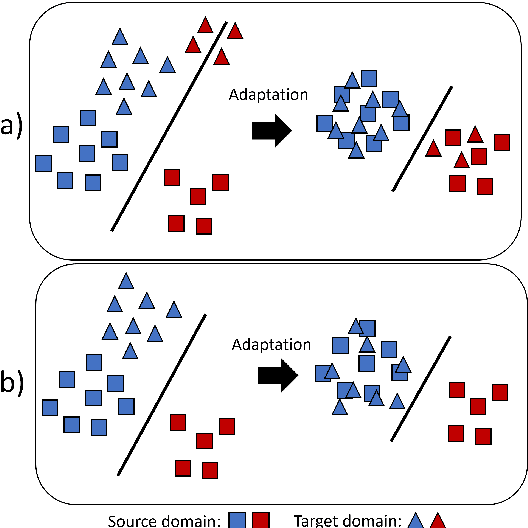
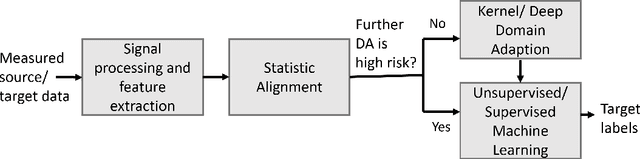
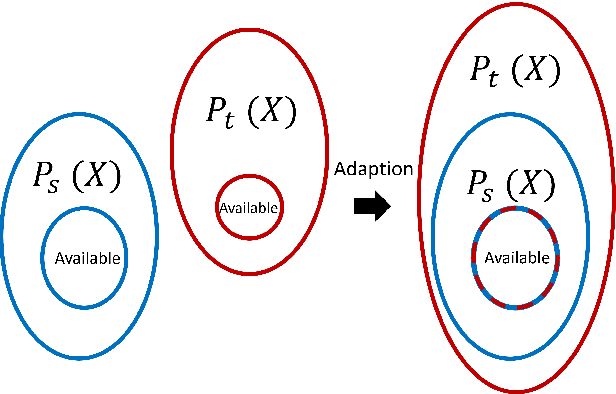
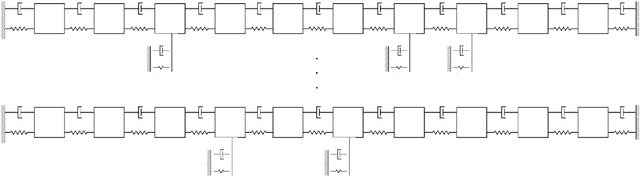
The practical application of structural health monitoring (SHM) is often limited by the availability of labelled data. Transfer learning - specifically in the form of domain adaptation (DA) - gives rise to the possibility of leveraging information from a population of physical or numerical structures, by inferring a mapping that aligns the feature spaces. Typical DA methods rely on nonparametric distance metrics, which require sufficient data to perform density estimation. In addition, these methods can be prone to performance degradation under class imbalance. To address these issues, statistic alignment (SA) is discussed, with a demonstration of how these methods can be made robust to class imbalance, including a special case of class imbalance called a partial DA scenario. SA is demonstrated to facilitate damage localisation with no target labels in a numerical case study, outperforming other state-of-the-art DA methods. It is then shown to be capable of aligning the feature spaces of a real heterogeneous population, the Z24 and KW51 bridges, with only 220 samples used from the KW51 bridge. Finally, in scenarios where more complex mappings are required for knowledge transfer, SA is shown to be a vital pre-processing tool, increasing the performance of established DA methods.