 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum SVGD-EM for Accelerated Maximum Marginal Likelihood Estimation
Mar 09, 2026Maximum marginal likelihood estimation (MMLE) can be formulated as the optimization of a free energy functional. From this viewpoint, the Expectation-Maximisation (EM) algorithm admits a natural interpretation as a coordinate descent method over the joint space of model parameters and probability measures. Recently, a significant body of work has adopted this perspective, leading to interacting particle algorithms for MMLE. In this paper, we propose an accelerated version of one such procedure, based on Stein variational gradient descent (SVGD), by introducing Nesterov acceleration in both the parameter updates and in the space of probability measures. The resulting method, termed Momentum SVGD-EM, consistently accelerates convergence in terms of required iterations across various tasks of increasing difficulty, demonstrating effectiveness in both low- and high-dimensional settings.
Diffusion Path Samplers via Sequential Monte Carlo
Jan 29, 2026We develop a diffusion-based sampler for target distributions known up to a normalising constant. To this end, we rely on the well-known diffusion path that smoothly interpolates between a (simple) base distribution and the target distribution, widely used in diffusion models. Our approach is based on a practical implementation of diffusion-annealed Langevin Monte Carlo, which approximates the diffusion path with convergence guarantees. We tackle the score estimation problem by developing an efficient sequential Monte Carlo sampler that evolves auxiliary variables from conditional distributions along the path, which provides principled score estimates for time-varying distributions. We further develop novel control variate schedules that minimise the variance of these score estimates. Finally, we provide theoretical guarantees and empirically demonstrate the effectiveness of our method on several synthetic and real-world datasets.
Efficient Stochastic Optimisation via Sequential Monte Carlo
Jan 29, 2026The problem of optimising functions with intractable gradients frequently arise in machine learning and statistics, ranging from maximum marginal likelihood estimation procedures to fine-tuning of generative models. Stochastic approximation methods for this class of problems typically require inner sampling loops to obtain (biased) stochastic gradient estimates, which rapidly becomes computationally expensive. In this work, we develop sequential Monte Carlo (SMC) samplers for optimisation of functions with intractable gradients. Our approach replaces expensive inner sampling methods with efficient SMC approximations, which can result in significant computational gains. We establish convergence results for the basic recursions defined by our methodology which SMC samplers approximate. We demonstrate the effectiveness of our approach on the reward-tuning of energy-based models within various settings.
Uniform-in-time convergence bounds for Persistent Contrastive Divergence Algorithms
Oct 02, 2025We propose a continuous-time formulation of persistent contrastive divergence (PCD) for maximum likelihood estimation (MLE) of unnormalised densities. Our approach expresses PCD as a coupled, multiscale system of stochastic differential equations (SDEs), which perform optimisation of the parameter and sampling of the associated parametrised density, simultaneously. From this novel formulation, we are able to derive explicit bounds for the error between the PCD iterates and the MLE solution for the model parameter. This is made possible by deriving uniform-in-time (UiT) bounds for the difference in moments between the multiscale system and the averaged regime. An efficient implementation of the continuous-time scheme is introduced, leveraging a class of explicit, stable intregators, stochastic orthogonal Runge-Kutta Chebyshev (S-ROCK), for which we provide explicit error estimates in the long-time regime. This leads to a novel method for training energy-based models (EBMs) with explicit error guarantees.
Sampling by averaging: A multiscale approach to score estimation
Aug 20, 2025We introduce a novel framework for efficient sampling from complex, unnormalised target distributions by exploiting multiscale dynamics. Traditional score-based sampling methods either rely on learned approximations of the score function or involve computationally expensive nested Markov chain Monte Carlo (MCMC) loops. In contrast, the proposed approach leverages stochastic averaging within a slow-fast system of stochastic differential equations (SDEs) to estimate intermediate scores along a diffusion path without training or inner-loop MCMC. Two algorithms are developed under this framework: MultALMC, which uses multiscale annealed Langevin dynamics, and MultCDiff, based on multiscale controlled diffusions for the reverse-time Ornstein-Uhlenbeck process. Both overdamped and underdamped variants are considered, with theoretical guarantees of convergence to the desired diffusion path. The framework is extended to handle heavy-tailed target distributions using Student's t-based noise models and tailored fast-process dynamics. Empirical results across synthetic and real-world benchmarks, including multimodal and high-dimensional distributions, demonstrate that the proposed methods are competitive with existing samplers in terms of accuracy and efficiency, without the need for learned models.
Learning Latent Variable Models via Jarzynski-adjusted Langevin Algorithm
May 23, 2025
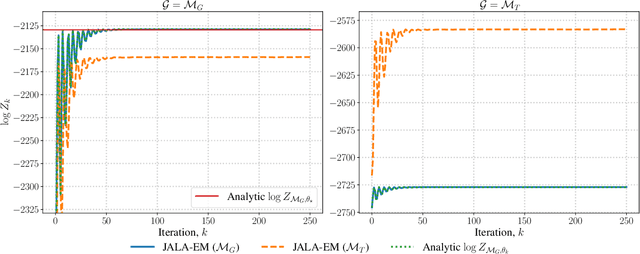


We utilise a sampler originating from nonequilibrium statistical mechanics, termed here Jarzynski-adjusted Langevin algorithm (JALA), to build statistical estimation methods in latent variable models. We achieve this by leveraging Jarzynski's equality and developing algorithms based on a weighted version of the unadjusted Langevin algorithm (ULA) with recursively updated weights. Adapting this for latent variable models, we develop a sequential Monte Carlo (SMC) method that provides the maximum marginal likelihood estimate of the parameters, termed JALA-EM. Under suitable regularity assumptions on the marginal likelihood, we provide a nonasymptotic analysis of the JALA-EM scheme implemented with stochastic gradient descent and show that it provably converges to the maximum marginal likelihood estimate. We demonstrate the performance of JALA-EM on a variety of latent variable models and show that it performs comparably to existing methods in terms of accuracy and computational efficiency. Importantly, the ability to recursively estimate marginal likelihoods - an uncommon feature among scalable methods - makes our approach particularly suited for model selection, which we validate through dedicated experiments.
Training Latent Diffusion Models with Interacting Particle Algorithms
May 18, 2025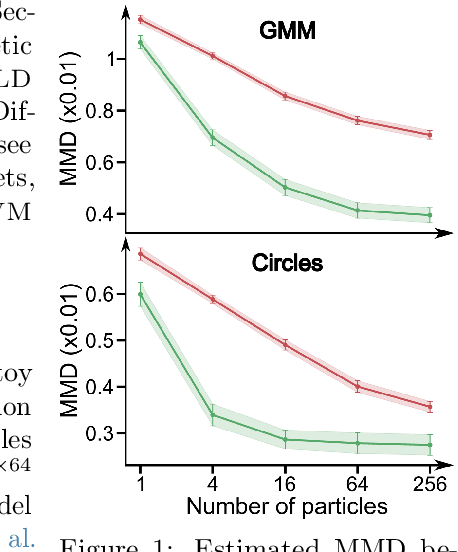

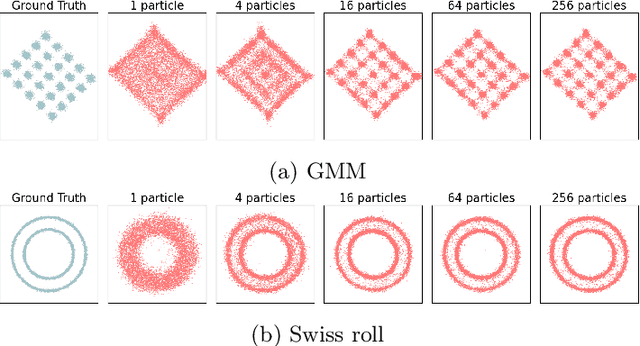
We introduce a novel particle-based algorithm for end-to-end training of latent diffusion models. We reformulate the training task as minimizing a free energy functional and obtain a gradient flow that does so. By approximating the latter with a system of interacting particles, we obtain the algorithm, which we underpin it theoretically by providing error guarantees. The novel algorithm compares favorably in experiments with previous particle-based methods and variational inference analogues.
On the contraction properties of Sinkhorn semigroups
Mar 12, 2025We develop a novel semigroup contraction analysis based on Lyapunov techniques to prove the exponential convergence of Sinkhorn equations on weighted Banach spaces. This operator-theoretic framework yields exponential decays of Sinkhorn iterates towards Schr\"odinger bridges with respect to general classes of $\phi$-divergences as well as in weighted Banach spaces. To the best of our knowledge, these are the first results of this type in the literature on entropic transport and the Sinkhorn algorithm. We also illustrate the impact of these results in the context of multivariate linear Gaussian models as well as statistical finite mixture models including Gaussian-kernel density estimation of complex data distributions arising in generative models.
Non-asymptotic Analysis of Diffusion Annealed Langevin Monte Carlo for Generative Modelling
Feb 13, 2025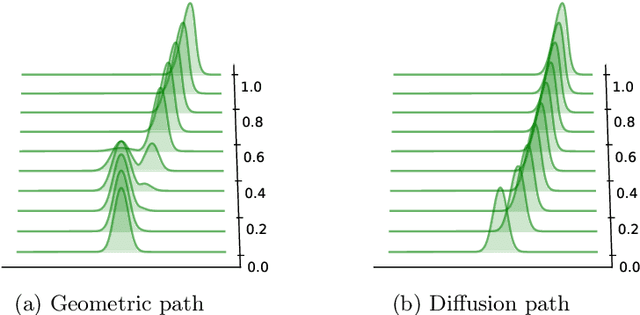
We investigate the theoretical properties of general diffusion (interpolation) paths and their Langevin Monte Carlo implementation, referred to as diffusion annealed Langevin Monte Carlo (DALMC), under weak conditions on the data distribution. Specifically, we analyse and provide non-asymptotic error bounds for the annealed Langevin dynamics where the path of distributions is defined as Gaussian convolutions of the data distribution as in diffusion models. We then extend our results to recently proposed heavy-tailed (Student's t) diffusion paths, demonstrating their theoretical properties for heavy-tailed data distributions for the first time. Our analysis provides theoretical guarantees for a class of score-based generative models that interpolate between a simple distribution (Gaussian or Student's t) and the data distribution in finite time. This approach offers a broader perspective compared to standard score-based diffusion approaches, which are typically based on a forward Ornstein-Uhlenbeck (OU) noising process.
Gaussian entropic optimal transport: Schrödinger bridges and the Sinkhorn algorithm
Dec 24, 2024Entropic optimal transport problems are regularized versions of optimal transport problems. These models play an increasingly important role in machine learning and generative modelling. For finite spaces, these problems are commonly solved using Sinkhorn algorithm (a.k.a. iterative proportional fitting procedure). However, in more general settings the Sinkhorn iterations are based on nonlinear conditional/conjugate transformations and exact finite-dimensional solutions cannot be computed. This article presents a finite-dimensional recursive formulation of the iterative proportional fitting procedure for general Gaussian multivariate models. As expected, this recursive formulation is closely related to the celebrated Kalman filter and related Riccati matrix difference equations, and it yields algorithms that can be implemented in practical settings without further approximations. We extend this filtering methodology to develop a refined and self-contained convergence analysis of Gaussian Sinkhorn algorithms, including closed form expressions of entropic transport maps and Schr\"odinger bridges.