 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Self-Training for Unsupervised Machine Translation
Mar 17, 2026We present an ensemble-driven self-training framework for unsupervised neural machine translation (UNMT). Starting from a primary language pair, we train multiple UNMT models that share the same translation task but differ in an auxiliary language, inducing structured diversity across models. We then generate pseudo-translations for the primary pair using token-level ensemble decoding, averaging model predictions in both directions. These ensemble outputs are used as synthetic parallel data to further train each model, allowing the models to improve via shared supervision. At deployment time, we select a single model by validation performance, preserving single-model inference cost. Experiments show statistically significant improvements over single-model UNMT baselines, with mean gains of 1.7 chrF when translating from English and 0.67 chrF when translating into English.
Pro-AI Bias in Large Language Models
Jan 20, 2026Large language models (LLMs) are increasingly employed for decision-support across multiple domains. We investigate whether these models display a systematic preferential bias in favor of artificial intelligence (AI) itself. Across three complementary experiments, we find consistent evidence of pro-AI bias. First, we show that LLMs disproportionately recommend AI-related options in response to diverse advice-seeking queries, with proprietary models doing so almost deterministically. Second, we demonstrate that models systematically overestimate salaries for AI-related jobs relative to closely matched non-AI jobs, with proprietary models overestimating AI salaries more by 10 percentage points. Finally, probing internal representations of open-weight models reveals that ``Artificial Intelligence'' exhibits the highest similarity to generic prompts for academic fields under positive, negative, and neutral framings alike, indicating valence-invariant representational centrality. These patterns suggest that LLM-generated advice and valuation can systematically skew choices and perceptions in high-stakes decisions.
Understanding the Logical Capabilities of Large Language Models via Out-of-Context Representation Learning
Mar 13, 2025

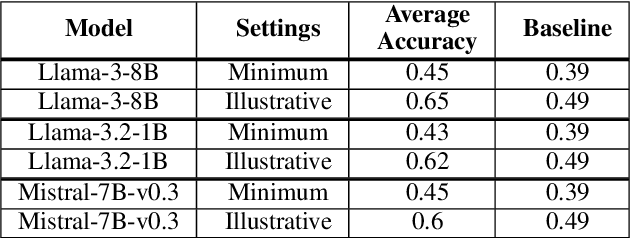
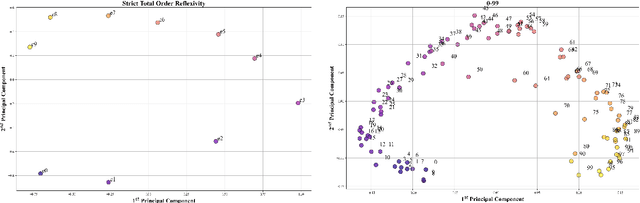
We study the capabilities of Large Language Models (LLM) on binary relations, a ubiquitous concept in math employed in most reasoning, math and logic benchmarks. This work focuses on equality, inequality, and inclusion, along with the properties they satisfy, such as ir/reflexivity, a/symmetry, transitivity, and logical complexity (e.g., number of reasoning ``hops''). We propose an alternative to in-context learning that trains only the representations of newly introduced tokens, namely out-of-context representation learning. This method mitigates linguistic biases already present in a model and, differently from in-context learning, does not rely on external information or illustrations. We argue out-of-context representation learning as a better alternative to in-context learning and fine-tuning to evaluate the capabilities of LLMs on logic tasks that are the building blocks of more complex reasoning benchmarks.
Voter Priming Campaigns: Strategies, Equilibria, and Algorithms
Dec 17, 2024Issue salience is a major determinant in voters' decisions. Candidates and political parties campaign to shift salience to their advantage - a process termed priming. We study the dynamics, strategies and equilibria of campaign spending for voter priming in multi-issue multi-party settings. We consider both parliamentary elections, where parties aim to maximize their share of votes, and various settings for presidential elections, where the winner takes all. For parliamentary elections, we show that pure equilibrium spending always exists and can be computed in time linear in the number of voters. For two parties and all settings, a spending equilibrium exists such that each party invests only in a single issue, and an equilibrium can be computed in time that is polynomial in the number of issues and linear in the number of voters. We also show that in most presidential settings no equilibrium exists. Additional properties of optimal campaign strategies are also studied.
Bayesian Persuasion with Externalities: Exploiting Agent Types
Dec 17, 2024We study a Bayesian persuasion problem with externalities. In this model, a principal sends signals to inform multiple agents about the state of the world. Simultaneously, due to the existence of externalities in the agents' utilities, the principal also acts as a correlation device to correlate the agents' actions. We consider the setting where the agents are categorized into a small number of types. Agents of the same type share identical utility functions and are treated equitably in the utility functions of both other agents and the principal. We study the problem of computing optimal signaling strategies for the principal, under three different types of signaling channels: public, private, and semi-private. Our results include revelation-principle-style characterizations of optimal signaling strategies, linear programming formulations, and analysis of in/tractability of the optimization problems. It is demonstrated that when the maximum number of deviating agents is bounded by a constant, our LP-based formulations compute optimal signaling strategies in polynomial time. Otherwise, the problems are NP-hard.
Cognitive Effects in Large Language Models
Aug 28, 2023Large Language Models (LLMs) such as ChatGPT have received enormous attention over the past year and are now used by hundreds of millions of people every day. The rapid adoption of this technology naturally raises questions about the possible biases such models might exhibit. In this work, we tested one of these models (GPT-3) on a range of cognitive effects, which are systematic patterns that are usually found in human cognitive tasks. We found that LLMs are indeed prone to several human cognitive effects. Specifically, we show that the priming, distance, SNARC, and size congruity effects were presented with GPT-3, while the anchoring effect is absent. We describe our methodology, and specifically the way we converted real-world experiments to text-based experiments. Finally, we speculate on the possible reasons why GPT-3 exhibits these effects and discuss whether they are imitated or reinvented.