 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-GBS3FCM -- KNN Graph-Based Safe Semi-Supervised Fuzzy C-Means
Nov 22, 2024Clustering data using prior domain knowledge, starting from a partially labeled set, has recently been widely investigated. Often referred to as semi-supervised clustering, this approach leverages labeled data to enhance clustering accuracy. To maximize algorithm performance, it is crucial to ensure the safety of this prior knowledge. Methods addressing this concern are termed safe semi-supervised clustering (S3C) algorithms. This paper introduces the KNN graph-based safety-aware semi-supervised fuzzy c-means algorithm (K-GBS3FCM), which dynamically assesses neighborhood relationships between labeled and unlabeled data using the K-Nearest Neighbors (KNN) algorithm. This approach aims to optimize the use of labeled data while minimizing the adverse effects of incorrect labels. Additionally, it is proposed a mechanism that adjusts the influence of labeled data on unlabeled ones through regularization parameters and the average safety degree. Experimental results on multiple benchmark datasets demonstrate that the graph-based approach effectively leverages prior knowledge to enhance clustering accuracy. The proposed method was significantly superior in 64% of the 56 test configurations, obtaining higher levels of clustering accuracy when compared to other semi-supervised and traditional unsupervised methods. This research highlights the potential of integrating graph-based approaches, such as KNN, with established techniques to develop advanced clustering algorithms, offering significant applications in fields that rely on both labeled and unlabeled data for more effective clustering.
Expectation vs. Reality: Towards Verification of Psychological Games
Nov 08, 2024Game theory provides an effective way to model strategic interactions among rational agents. In the context of formal verification, these ideas can be used to produce guarantees on the correctness of multi-agent systems, with a diverse range of applications from computer security to autonomous driving. Psychological games (PGs) were developed as a way to model and analyse agents with belief-dependent motivations, opening up the possibility to model how human emotions can influence behaviour. In PGs, players' utilities depend not only on what actually happens (which strategies players choose to adopt), but also on what the players had expected to happen (their belief as to the strategies that would be played). Despite receiving much attention in fields such as economics and psychology, very little consideration has been given to their applicability to problems in computer science, nor to practical algorithms and tool support. In this paper, we start to bridge that gap, proposing methods to solve PGs and implementing them within PRISM-games, a formal verification tool for stochastic games. We discuss how to model these games, highlight specific challenges for their analysis and illustrate the usefulness of our approach on several case studies, including human behaviour in traffic scenarios.
HSVI-based Online Minimax Strategies for Partially Observable Stochastic Games with Neural Perception Mechanisms
Apr 16, 2024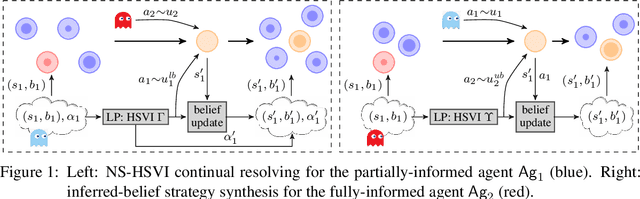
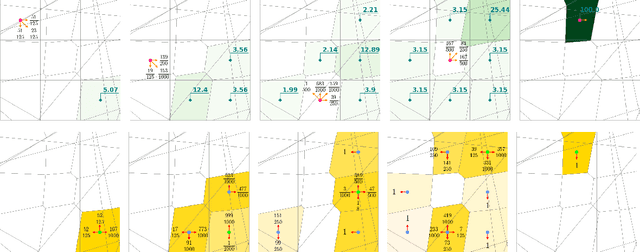
We consider a variant of continuous-state partially-observable stochastic games with neural perception mechanisms and an asymmetric information structure. One agent has partial information, with the observation function implemented as a neural network, while the other agent is assumed to have full knowledge of the state. We present, for the first time, an efficient online method to compute an $\varepsilon$-minimax strategy profile, which requires only one linear program to be solved for each agent at every stage, instead of a complex estimation of opponent counterfactual values. For the partially-informed agent, we propose a continual resolving approach which uses lower bounds, pre-computed offline with heuristic search value iteration (HSVI), instead of opponent counterfactual values. This inherits the soundness of continual resolving at the cost of pre-computing the bound. For the fully-informed agent, we propose an inferred-belief strategy, where the agent maintains an inferred belief about the belief of the partially-informed agent based on (offline) upper bounds from HSVI, guaranteeing $\varepsilon$-distance to the value of the game at the initial belief known to both agents.
Partially Observable Stochastic Games with Neural Perception Mechanisms
Oct 17, 2023Stochastic games are a well established model for multi-agent sequential decision making under uncertainty. In reality, though, agents have only partial observability of their environment, which makes the problem computationally challenging, even in the single-agent setting of partially observable Markov decision processes. Furthermore, in practice, agents increasingly perceive their environment using data-driven approaches such as neural networks trained on continuous data. To tackle this problem, we propose the model of neuro-symbolic partially-observable stochastic games (NS-POSGs), a variant of continuous-space concurrent stochastic games that explicitly incorporates perception mechanisms. We focus on a one-sided setting, comprising a partially-informed agent with discrete, data-driven observations and a fully-informed agent with continuous observations. We present a new point-based method, called one-sided NS-HSVI, for approximating values of one-sided NS-POSGs and implement it based on the popular particle-based beliefs, showing that it has closed forms for computing values of interest. We provide experimental results to demonstrate the practical applicability of our method for neural networks whose preimage is in polyhedral form.
Point-based Value Iteration for Neuro-Symbolic POMDPs
Jun 30, 2023Neuro-symbolic artificial intelligence is an emerging area that combines traditional symbolic techniques with neural networks. In this paper, we consider its application to sequential decision making under uncertainty. We introduce neuro-symbolic partially observable Markov decision processes (NS-POMDPs), which model an agent that perceives a continuous-state environment using a neural network and makes decisions symbolically, and study the problem of optimising discounted cumulative rewards. This requires functions over continuous-state beliefs, for which we propose a novel piecewise linear and convex representation (P-PWLC) in terms of polyhedra covering the continuous-state space and value vectors, and extend Bellman backups to this representation. We prove the convexity and continuity of value functions and present two value iteration algorithms that ensure finite representability by exploiting the underlying structure of the continuous-state model and the neural perception mechanism. The first is a classical (exact) value iteration algorithm extending $\alpha$-functions of Porta et al (2006) to the P-PWLC representation for continuous-state spaces. The second is a point-based (approximate) method called NS-HSVI, which uses the P-PWLC representation and belief-value induced functions to approximate value functions from below and above for two types of beliefs, particle-based and region-based. Using a prototype implementation, we show the practical applicability of our approach on two case studies that employ (trained) ReLU neural networks as perception functions, dynamic car parking and an aircraft collision avoidance system, by synthesising (approximately) optimal strategies. An experimental comparison with the finite-state POMDP solver SARSOP demonstrates that NS-HSVI is more robust to particle disturbances.
Strategy Synthesis for Zero-sum Neuro-symbolic Concurrent Stochastic Games
Feb 13, 2022
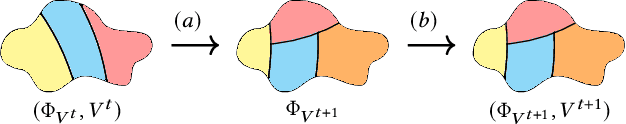
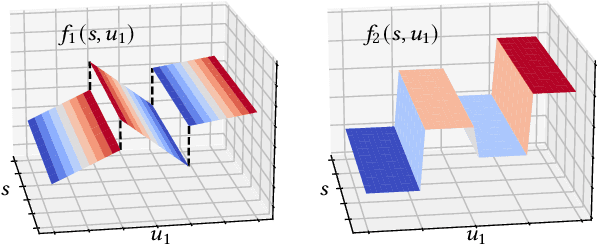
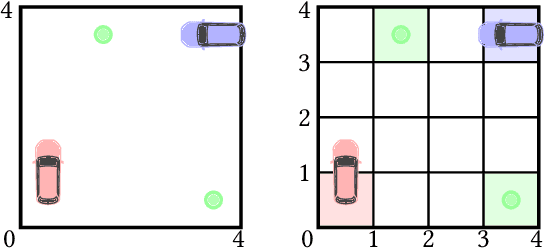
Neuro-symbolic approaches to artificial intelligence, which combine neural networks with classical symbolic techniques, are growing in prominence, necessitating formal approaches to reason about their correctness. We propose a novel modelling formalism called neuro-symbolic concurrent stochastic games (NS-CSGs), which comprise a set of probabilistic finite-state agents interacting in a shared continuous-state environment, observed through perception mechanisms implemented as neural networks. Since the environment state space is continuous, we focus on the class of NS-CSGs with Borel state spaces and Borel measurability restrictions on the components of the model. We consider the problem of zero-sum discounted cumulative reward, proving that NS-CSGs are determined and therefore have a value which corresponds to a unique fixed point. From an algorithmic perspective, existing methods to compute values and optimal strategies for CSGs focus on finite state spaces. We present, for the first time, value iteration and policy iteration algorithms to solve a class of uncountable state space CSGs, and prove their convergence. Our approach works by formulating piecewise linear or constant representations of the value functions and strategies of NS-CSGs. We validate the approach with a prototype implementation applied to a dynamic vehicle parking example.