 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaintenance Strategies for Sewer Pipes with Multi-State Degradation and Deep Reinforcement Learning
Jul 17, 2024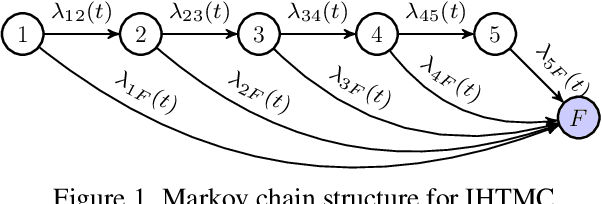

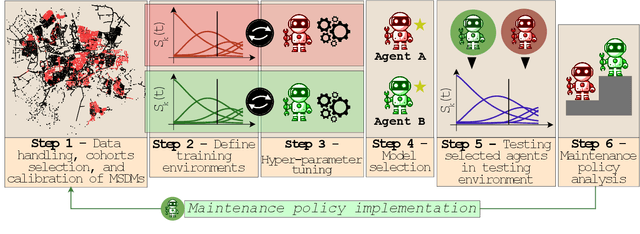

Large-scale infrastructure systems are crucial for societal welfare, and their effective management requires strategic forecasting and intervention methods that account for various complexities. Our study addresses two challenges within the Prognostics and Health Management (PHM) framework applied to sewer assets: modeling pipe degradation across severity levels and developing effective maintenance policies. We employ Multi-State Degradation Models (MSDM) to represent the stochastic degradation process in sewer pipes and use Deep Reinforcement Learning (DRL) to devise maintenance strategies. A case study of a Dutch sewer network exemplifies our methodology. Our findings demonstrate the model's effectiveness in generating intelligent, cost-saving maintenance strategies that surpass heuristics. It adapts its management strategy based on the pipe's age, opting for a passive approach for newer pipes and transitioning to active strategies for older ones to prevent failures and reduce costs. This research highlights DRL's potential in optimizing maintenance policies. Future research will aim improve the model by incorporating partial observability, exploring various reinforcement learning algorithms, and extending this methodology to comprehensive infrastructure management.
A Maintenance Planning Framework using Online and Offline Deep Reinforcement Learning
Aug 01, 2022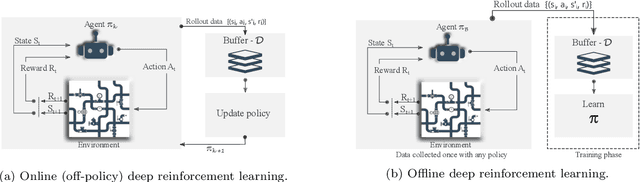
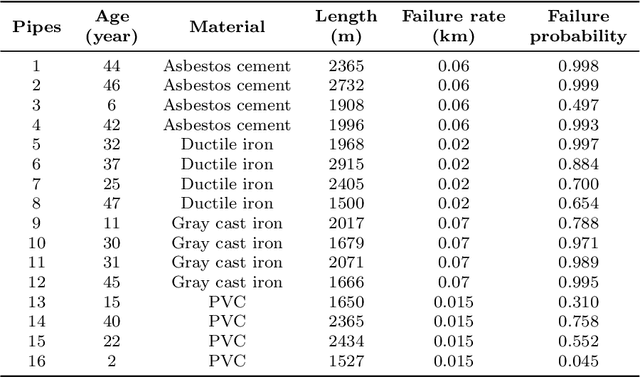
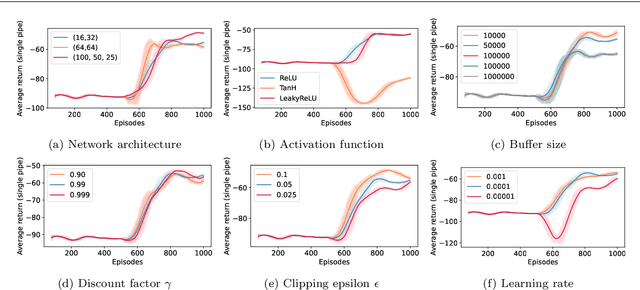
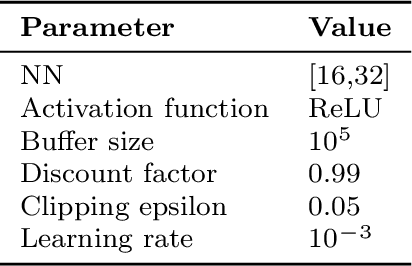
Cost-effective asset management is an area of interest across several industries. Specifically, this paper develops a deep reinforcement learning (DRL) solution to automatically determine an optimal rehabilitation policy for continuously deteriorating water pipes. We approach the problem of rehabilitation planning in an online and offline DRL setting. In online DRL, the agent interacts with a simulated environment of multiple pipes with distinct length, material, and failure rate characteristics. We train the agent using deep Q-learning (DQN) to learn an optimal policy with minimal average costs and reduced failure probability. In offline learning, the agent uses static data, e.g., DQN replay data, to learn an optimal policy via a conservative Q-learning algorithm without further interactions with the environment. We demonstrate that DRL-based policies improve over standard preventive, corrective, and greedy planning alternatives. Additionally, learning from the fixed DQN replay dataset surpasses the online DQN setting. The results warrant that the existing deterioration profiles of water pipes consisting of large and diverse states and action trajectories provide a valuable avenue to learn rehabilitation policies in the offline setting without needing a simulator.