 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning for Learning to Dispatch for Job Shop Scheduling
Sep 16, 2024



The Job Shop Scheduling Problem (JSSP) is a complex combinatorial optimization problem. There has been growing interest in using online Reinforcement Learning (RL) for JSSP. While online RL can quickly find acceptable solutions, especially for larger problems, it produces lower-quality results than traditional methods like Constraint Programming (CP). A significant downside of online RL is that it cannot learn from existing data, such as solutions generated from CP, requiring them to train from scratch, leading to sample inefficiency and making them unable to learn from more optimal examples. We introduce Offline Reinforcement Learning for Learning to Dispatch (Offline-LD), a novel approach for JSSP that addresses these limitations. Offline-LD adapts two CQL-based Q-learning methods (mQRDQN and discrete mSAC) for maskable action spaces, introduces a new entropy bonus modification for discrete SAC, and exploits reward normalization through preprocessing. Our experiments show that Offline-LD outperforms online RL on both generated and benchmark instances. By introducing noise into the dataset, we achieve similar or better results than those obtained from the expert dataset, indicating that a more diverse training set is preferable because it contains counterfactual information.
Deep Multi-Objective Reinforcement Learning for Utility-Based Infrastructural Maintenance Optimization
Jun 10, 2024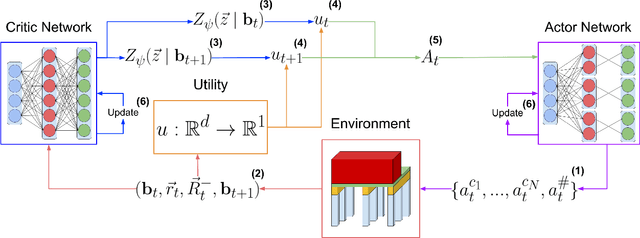
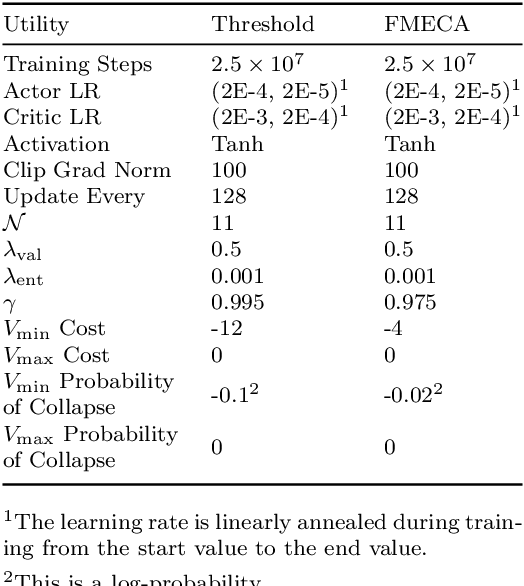
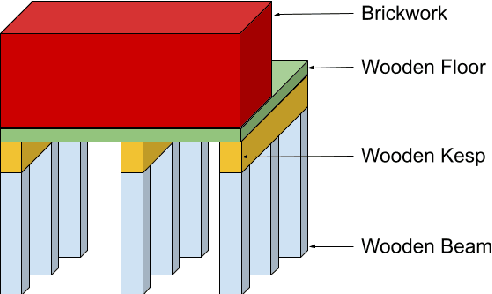

In this paper, we introduce Multi-Objective Deep Centralized Multi-Agent Actor-Critic (MO- DCMAC), a multi-objective reinforcement learning (MORL) method for infrastructural maintenance optimization, an area traditionally dominated by single-objective reinforcement learning (RL) approaches. Previous single-objective RL methods combine multiple objectives, such as probability of collapse and cost, into a singular reward signal through reward-shaping. In contrast, MO-DCMAC can optimize a policy for multiple objectives directly, even when the utility function is non-linear. We evaluated MO-DCMAC using two utility functions, which use probability of collapse and cost as input. The first utility function is the Threshold utility, in which MO-DCMAC should minimize cost so that the probability of collapse is never above the threshold. The second is based on the Failure Mode, Effects, and Criticality Analysis (FMECA) methodology used by asset managers to asses maintenance plans. We evaluated MO-DCMAC, with both utility functions, in multiple maintenance environments, including ones based on a case study of the historical quay walls of Amsterdam. The performance of MO-DCMAC was compared against multiple rule-based policies based on heuristics currently used for constructing maintenance plans. Our results demonstrate that MO-DCMAC outperforms traditional rule-based policies across various environments and utility functions.