 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoders for Anomaly Detection are Unreliable
Jan 23, 2025

Autoencoders are frequently used for anomaly detection, both in the unsupervised and semi-supervised settings. They rely on the assumption that when trained using the reconstruction loss, they will be able to reconstruct normal data more accurately than anomalous data. Some recent works have posited that this assumption may not always hold, but little has been done to study the validity of the assumption in theory. In this work we show that this assumption indeed does not hold, and illustrate that anomalies, lying far away from normal data, can be perfectly reconstructed in practice. We revisit the theory of failure of linear autoencoders for anomaly detection by showing how they can perfectly reconstruct out of bounds, or extrapolate undesirably, and note how this can be dangerous in safety critical applications. We connect this to non-linear autoencoders through experiments on both tabular data and real-world image data, the two primary application areas of autoencoders for anomaly detection.
Acquiring Better Load Estimates by Combining Anomaly and Change-point Detection in Power Grid Time-series Measurements
May 28, 2024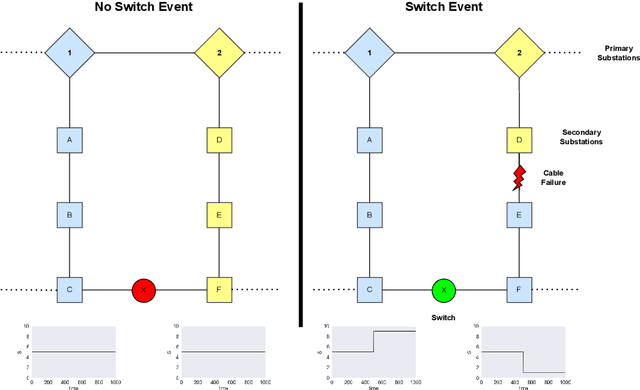

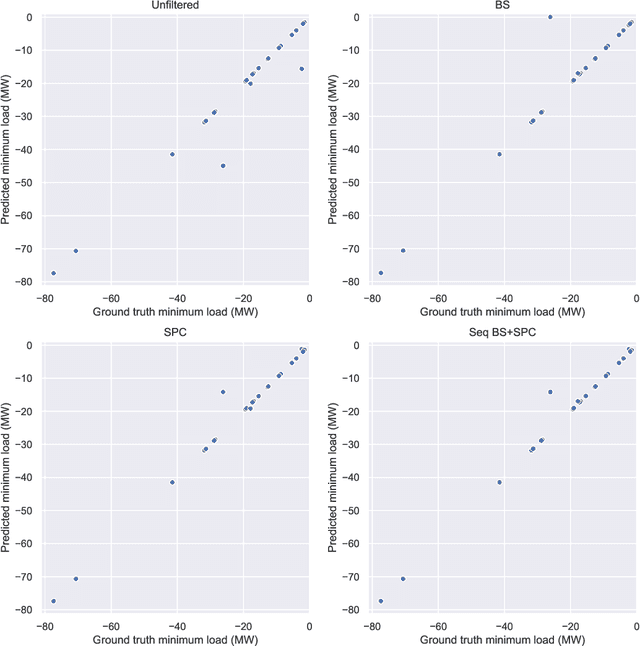
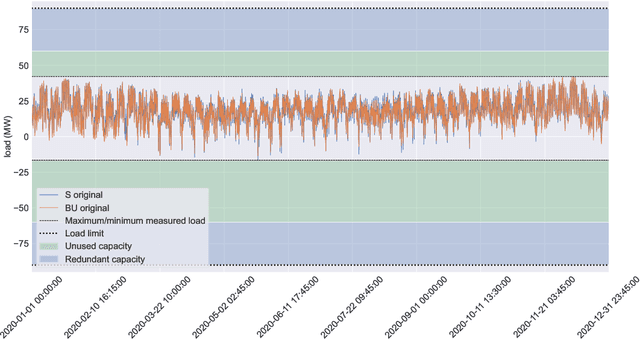
In this paper we present novel methodology for automatic anomaly and switch event filtering to improve load estimation in power grid systems. By leveraging unsupervised methods with supervised optimization, our approach prioritizes interpretability while ensuring robust and generalizable performance on unseen data. Through experimentation, a combination of binary segmentation for change point detection and statistical process control for anomaly detection emerges as the most effective strategy, specifically when ensembled in a novel sequential manner. Results indicate the clear wasted potential when filtering is not applied. The automatic load estimation is also fairly accurate, with approximately 90% of estimates falling within a 10% error margin, with only a single significant failure in both the minimum and maximum load estimates across 60 measurements in the test set. Our methodology's interpretability makes it particularly suitable for critical infrastructure planning, thereby enhancing decision-making processes.
Unsupervised anomaly detection algorithms on real-world data: how many do we need?
May 01, 2023



In this study we evaluate 32 unsupervised anomaly detection algorithms on 52 real-world multivariate tabular datasets, performing the largest comparison of unsupervised anomaly detection algorithms to date. On this collection of datasets, the $k$-thNN (distance to the $k$-nearest neighbor) algorithm significantly outperforms the most other algorithms. Visualizing and then clustering the relative performance of the considered algorithms on all datasets, we identify two clear clusters: one with ``local'' datasets, and another with ``global'' datasets. ``Local'' anomalies occupy a region with low density when compared to nearby samples, while ``global'' occupy an overall low density region in the feature space. On the local datasets the $k$NN ($k$-nearest neighbor) algorithm comes out on top. On the global datasets, the EIF (extended isolation forest) algorithm performs the best. Also taking into consideration the algorithms' computational complexity, a toolbox with these three unsupervised anomaly detection algorithms suffices for finding anomalies in this representative collection of multivariate datasets. By providing access to code and datasets, our study can be easily reproduced and extended with more algorithms and/or datasets.