 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Hidden Objective Biases of Group-based Reinforcement Learning
Jan 08, 2026Group-based reinforcement learning methods, like Group Relative Policy Optimization (GRPO), are widely used nowadays to post-train large language models. Despite their empirical success, they exhibit structural mismatches between reward optimization and the underlying training objective. In this paper, we present a theoretical analysis of GRPO style methods by studying them within a unified surrogate formulation. This perspective reveals recurring properties that affect all the methods under analysis: (i) non-uniform group weighting induces systematic gradient biases on shared prefix tokens; (ii) interactions with the AdamW optimizer make training dynamics largely insensitive to reward scaling; and (iii) optimizer momentum can push policy updates beyond the intended clipping region under repeated optimization steps. We believe that these findings highlight fundamental limitations of current approaches and provide principled guidance for the design of future formulations.
KGQuest: Template-Driven QA Generation from Knowledge Graphs with LLM-Based Refinement
Nov 14, 2025



The generation of questions and answers (QA) from knowledge graphs (KG) plays a crucial role in the development and testing of educational platforms, dissemination tools, and large language models (LLM). However, existing approaches often struggle with scalability, linguistic quality, and factual consistency. This paper presents a scalable and deterministic pipeline for generating natural language QA from KGs, with an additional refinement step using LLMs to further enhance linguistic quality. The approach first clusters KG triplets based on their relations, creating reusable templates through natural language rules derived from the entity types of objects and relations. A module then leverages LLMs to refine these templates, improving clarity and coherence while preserving factual accuracy. Finally, the instantiation of answer options is achieved through a selection strategy that introduces distractors from the KG. Our experiments demonstrate that this hybrid approach efficiently generates high-quality QA pairs, combining scalability with fluency and linguistic precision.
MoRSE: Bridging the Gap in Cybersecurity Expertise with Retrieval Augmented Generation
Jul 22, 2024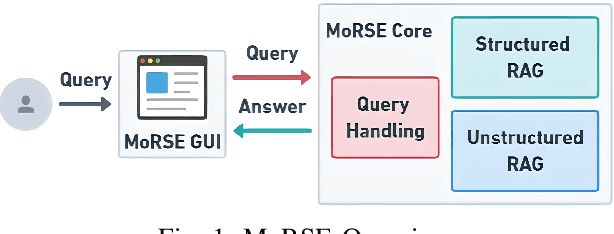
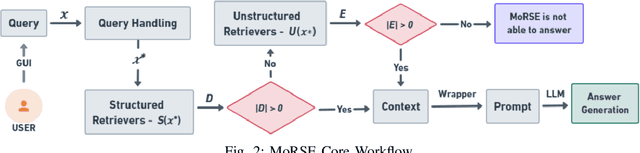
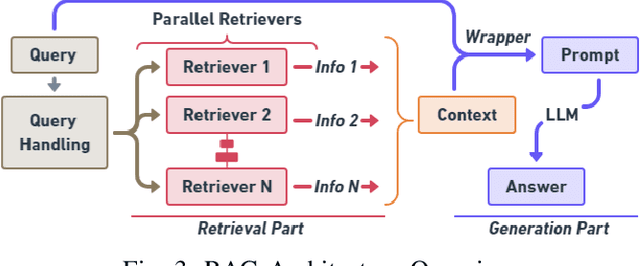
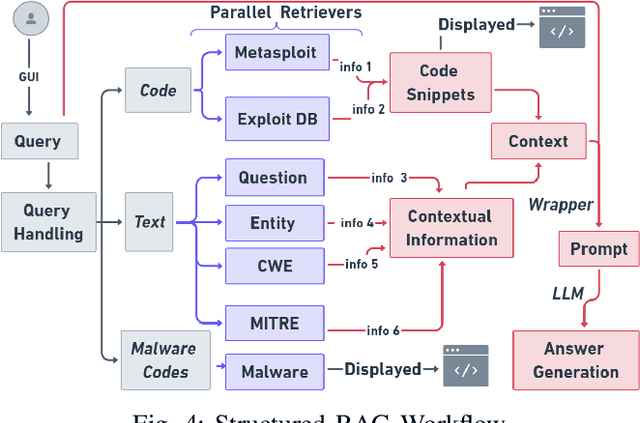
In this paper, we introduce MoRSE (Mixture of RAGs Security Experts), the first specialised AI chatbot for cybersecurity. MoRSE aims to provide comprehensive and complete knowledge about cybersecurity. MoRSE uses two RAG (Retrieval Augmented Generation) systems designed to retrieve and organize information from multidimensional cybersecurity contexts. MoRSE differs from traditional RAGs by using parallel retrievers that work together to retrieve semantically related information in different formats and structures. Unlike traditional Large Language Models (LLMs) that rely on Parametric Knowledge Bases, MoRSE retrieves relevant documents from Non-Parametric Knowledge Bases in response to user queries. Subsequently, MoRSE uses this information to generate accurate answers. In addition, MoRSE benefits from real-time updates to its knowledge bases, enabling continuous knowledge enrichment without retraining. We have evaluated the effectiveness of MoRSE against other state-of-the-art LLMs, evaluating the system on 600 cybersecurity specific questions. The experimental evaluation has shown that the improvement in terms of relevance and correctness of the answer is more than 10\% compared to known solutions such as GPT-4 and Mixtral 7x8.