 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Evaluation of Practical Video Analytics Systems for Face Detection and Recognition
Paper and Code
Oct 10, 2023
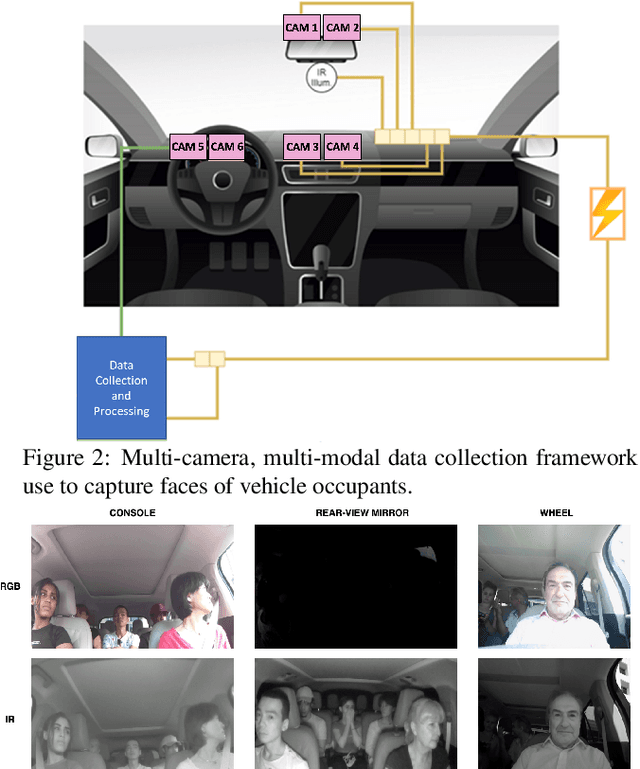


Practical video analytics systems that are deployed in bandwidth constrained environments like autonomous vehicles perform computer vision tasks such as face detection and recognition. In an end-to-end face analytics system, inputs are first compressed using popular video codecs like HEVC and then passed onto modules that perform face detection, alignment, and recognition sequentially. Typically, the modules of these systems are evaluated independently using task-specific imbalanced datasets that can misconstrue performance estimates. In this paper, we perform a thorough end-to-end evaluation of a face analytics system using a driving-specific dataset, which enables meaningful interpretations. We demonstrate how independent task evaluations, dataset imbalances, and inconsistent annotations can lead to incorrect system performance estimates. We propose strategies to create balanced evaluation subsets of our dataset and to make its annotations consistent across multiple analytics tasks and scenarios. We then evaluate the end-to-end system performance sequentially to account for task interdependencies. Our experiments show that our approach provides consistent, accurate, and interpretable estimates of the system's performance which is critical for real-world applications.