 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairSSD: Understanding Bias in Synthetic Speech Detectors
Paper and Code

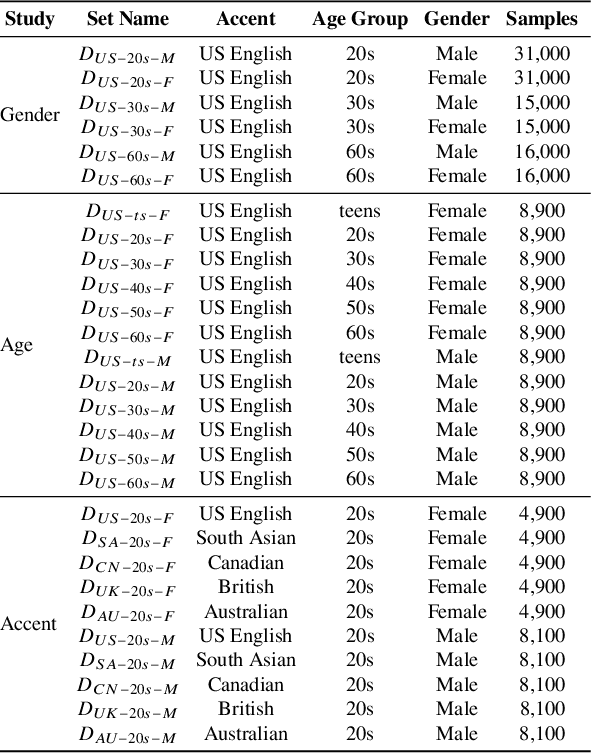
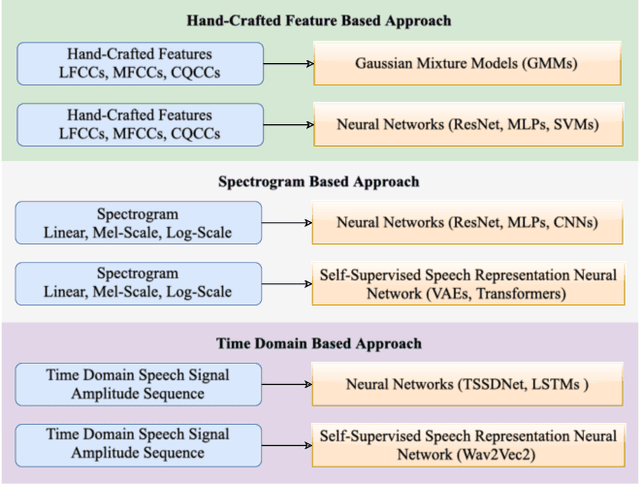
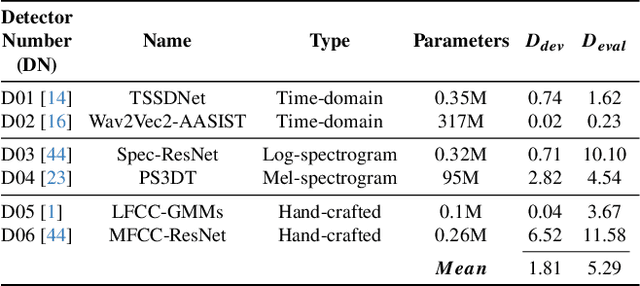
Methods that can generate synthetic speech which is perceptually indistinguishable from speech recorded by a human speaker, are easily available. Several incidents report misuse of synthetic speech generated from these methods to commit fraud. To counter such misuse, many methods have been proposed to detect synthetic speech. Some of these detectors are more interpretable, can generalize to detect synthetic speech in the wild and are robust to noise. However, limited work has been done on understanding bias in these detectors. In this work, we examine bias in existing synthetic speech detectors to determine if they will unfairly target a particular gender, age and accent group. We also inspect whether these detectors will have a higher misclassification rate for bona fide speech from speech-impaired speakers w.r.t fluent speakers. Extensive experiments on 6 existing synthetic speech detectors using more than 0.9 million speech signals demonstrate that most detectors are gender, age and accent biased, and future work is needed to ensure fairness. To support future research, we release our evaluation dataset, models used in our study and source code at https://gitlab.com/viper-purdue/fairssd.