 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatSplat: 3D Conversational Gaussian Splatting
Paper and Code

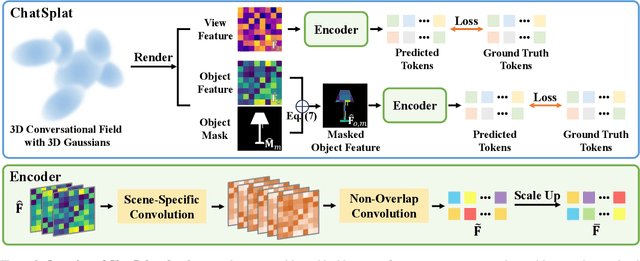

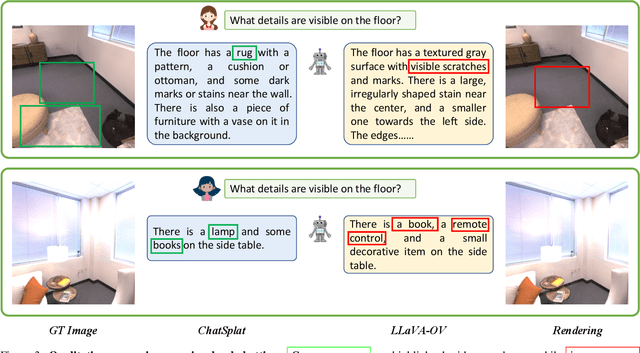
Humans naturally interact with their 3D surroundings using language, and modeling 3D language fields for scene understanding and interaction has gained growing interest. This paper introduces ChatSplat, a system that constructs a 3D language field, enabling rich chat-based interaction within 3D space. Unlike existing methods that primarily use CLIP-derived language features focused solely on segmentation, ChatSplat facilitates interaction on three levels: objects, views, and the entire 3D scene. For view-level interaction, we designed an encoder that encodes the rendered feature map of each view into tokens, which are then processed by a large language model (LLM) for conversation. At the scene level, ChatSplat combines multi-view tokens, enabling interactions that consider the entire scene. For object-level interaction, ChatSplat uses a patch-wise language embedding, unlike LangSplat's pixel-wise language embedding that implicitly includes mask and embedding. Here, we explicitly decouple the language embedding into separate mask and feature map representations, allowing more flexible object-level interaction. To address the challenge of learning 3D Gaussians posed by the complex and diverse distribution of language embeddings used in the LLM, we introduce a learnable normalization technique to standardize these embeddings, facilitating effective learning. Extensive experimental results demonstrate that ChatSplat supports multi-level interactions -- object, view, and scene -- within 3D space, enhancing both understanding and engagement.