 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of AI Generated Images Using Combined Uncertainty Measures and Particle Swarm Optimised Rejection Mechanism
Dec 20, 2025As AI-generated images become increasingly photorealistic, distinguishing them from natural images poses a growing challenge. This paper presents a robust detection framework that leverages multiple uncertainty measures to decide whether to trust or reject a model's predictions. We focus on three complementary techniques: Fisher Information, which captures the sensitivity of model parameters to input variations; entropy-based uncertainty from Monte Carlo Dropout, which reflects predictive variability; and predictive variance from a Deep Kernel Learning framework using a Gaussian Process classifier. To integrate these diverse uncertainty signals, Particle Swarm Optimisation is used to learn optimal weightings and determine an adaptive rejection threshold. The model is trained on Stable Diffusion-generated images and evaluated on GLIDE, VQDM, Midjourney, BigGAN, and StyleGAN3, each introducing significant distribution shifts. While standard metrics such as prediction probability and Fisher-based measures perform well in distribution, their effectiveness degrades under shift. In contrast, the Combined Uncertainty measure consistently achieves an incorrect rejection rate of approximately 70 percent on unseen generators, successfully filtering most misclassified AI samples. Although the system occasionally rejects correct predictions from newer generators, this conservative behaviour is acceptable, as rejected samples can support retraining. The framework maintains high acceptance of accurate predictions for natural images and in-domain AI data. Under adversarial attacks using FGSM and PGD, the Combined Uncertainty method rejects around 61 percent of successful attacks, while GP-based uncertainty alone achieves up to 80 percent. Overall, the results demonstrate that multi-source uncertainty fusion provides a resilient and adaptive solution for AI-generated image detection.
Bridge to Real Environment with Hardware-in-the-loop for Wireless Artificial Intelligence Paradigms
Sep 25, 2024



Nowadays, many machine learning (ML) solutions to improve the wireless standard IEEE802.11p for Vehicular Adhoc Network (VANET) are commonly evaluated in the simulated world. At the same time, this approach could be cost-effective compared to real-world testing due to the high cost of vehicles. There is a risk of unexpected outcomes when these solutions are implemented in the real world, potentially leading to wasted resources. To mitigate this challenge, the hardware-in-the-loop is the way to move forward as it enables the opportunity to test in the real world and simulated worlds together. Therefore, we have developed what we believe is the pioneering hardware-in-the-loop for testing artificial intelligence, multiple services, and HD map data (LiDAR), in both simulated and real-world settings.
Multi-agent Assessment with QoS Enhancement for HD Map Updates in a Vehicular Network
Jul 31, 2024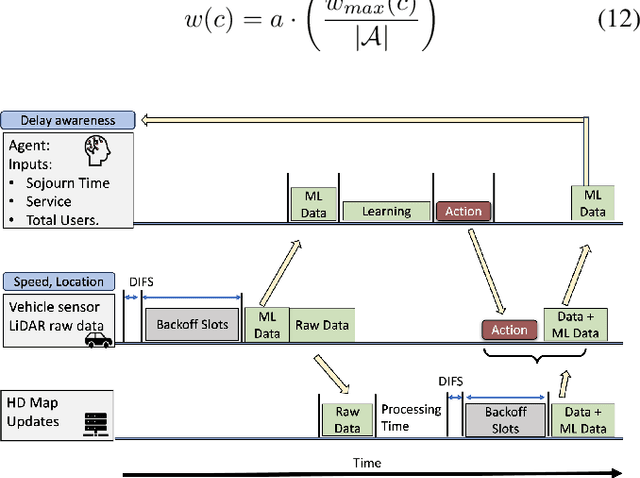
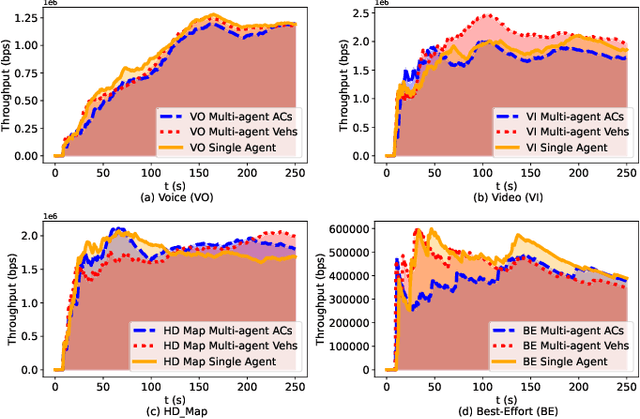
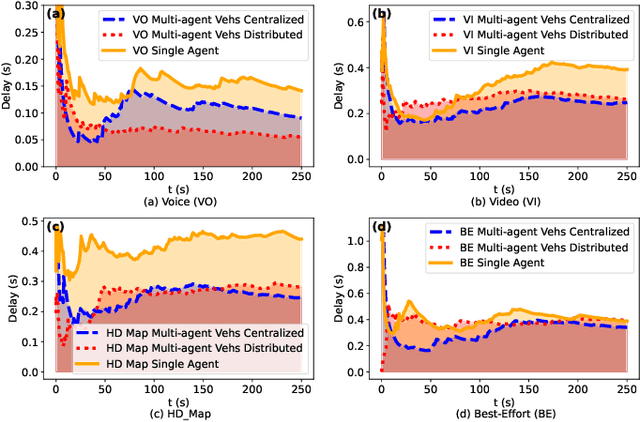
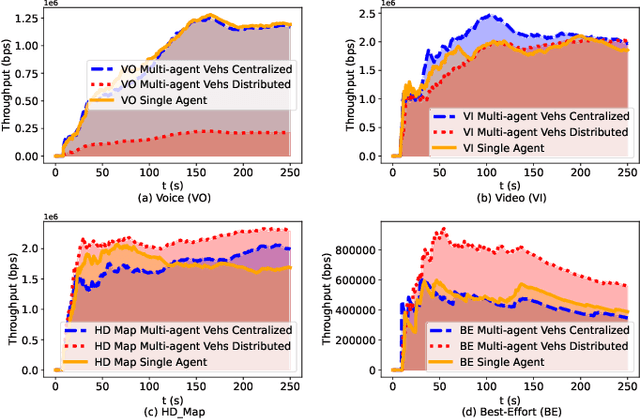
Reinforcement Learning (RL) algorithms have been used to address the challenging problems in the offloading process of vehicular ad hoc networks (VANET). More recently, they have been utilized to improve the dissemination of high-definition (HD) Maps. Nevertheless, implementing solutions such as deep Q-learning (DQN) and Actor-critic at the autonomous vehicle (AV) may lead to an increase in the computational load, causing a heavy burden on the computational devices and higher costs. Moreover, their implementation might raise compatibility issues between technologies due to the required modifications to the standards. Therefore, in this paper, we assess the scalability of an application utilizing a Q-learning single-agent solution in a distributed multi-agent environment. This application improves the network performance by taking advantage of a smaller state, and action space whilst using a multi-agent approach. The proposed solution is extensively evaluated with different test cases involving reward function considering individual or overall network performance, number of agents, and centralized and distributed learning comparison. The experimental results demonstrate that the time latencies of our proposed solution conducted in voice, video, HD Map, and best-effort cases have significant improvements, with 40.4%, 36%, 43%, and 12% respectively, compared to the performances with the single-agent approach.
Coverage-aware and Reinforcement Learning Using Multi-agent Approach for HD Map QoS in a Realistic Environment
Jul 19, 2024



One effective way to optimize the offloading process is by minimizing the transmission time. This is particularly true in a Vehicular Adhoc Network (VANET) where vehicles frequently download and upload High-definition (HD) map data which requires constant updates. This implies that latency and throughput requirements must be guaranteed by the wireless system. To achieve this, adjustable contention windows (CW) allocation strategies in the standard IEEE802.11p have been explored by numerous researchers. Nevertheless, their implementations demand alterations to the existing standard which is not always desirable. To address this issue, we proposed a Q-Learning algorithm that operates at the application layer. Moreover, it could be deployed in any wireless network thereby mitigating the compatibility issues. The solution has demonstrated a better network performance with relatively fewer optimization requirements as compared to the Deep Q Network (DQN) and Actor-Critic algorithms. The same is observed while evaluating the model in a multi-agent setup showing higher performance compared to the single-agent setup.
Enhancement of High-definition Map Update Service Through Coverage-aware and Reinforcement Learning
Feb 08, 2024



High-definition (HD) Map systems will play a pivotal role in advancing autonomous driving to a higher level, thanks to the significant improvement over traditional two-dimensional (2D) maps. Creating an HD Map requires a huge amount of on-road and off-road data. Typically, these raw datasets are collected and uploaded to cloud-based HD map service providers through vehicular networks. Nevertheless, there are challenges in transmitting the raw data over vehicular wireless channels due to the dynamic topology. As the number of vehicles increases, there is a detrimental impact on service quality, which acts as a barrier to a real-time HD Map system for collaborative driving in Autonomous Vehicles (AV). In this paper, to overcome network congestion, a Q-learning coverage-time-awareness algorithm is presented to optimize the quality of service for vehicular networks and HD map updates. The algorithm is evaluated in an environment that imitates a dynamic scenario where vehicles enter and leave. Results showed an improvement in latency for HD map data of $75\%$, $73\%$, and $10\%$ compared with IEEE802.11p without Quality of Service (QoS), IEEE802.11 with QoS, and IEEE802.11p with new access category (AC) for HD map, respectively.
Deep Reinforcement Learning based Evasion Generative Adversarial Network for Botnet Detection
Oct 06, 2022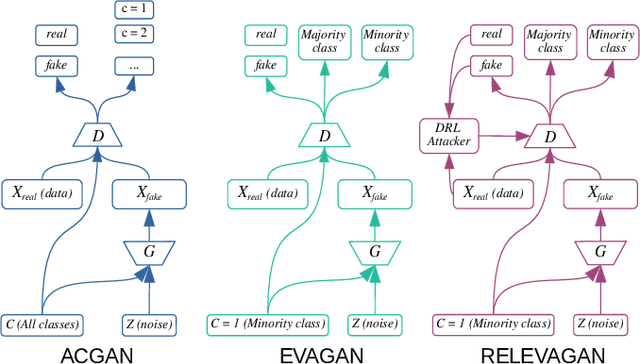
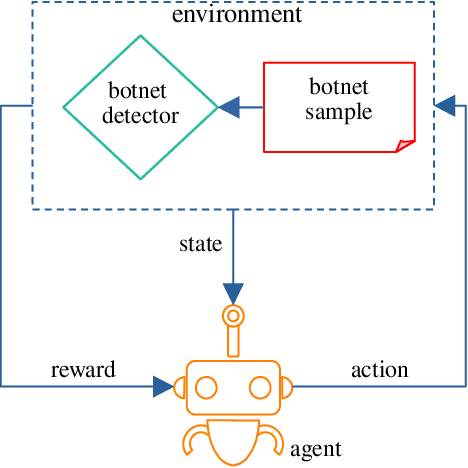
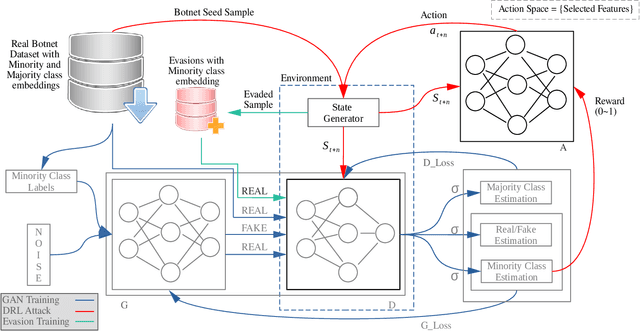
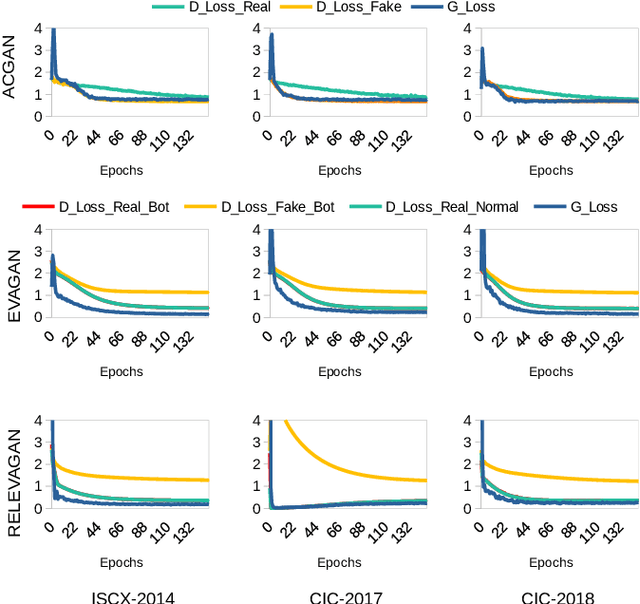
Botnet detectors based on machine learning are potential targets for adversarial evasion attacks. Several research works employ adversarial training with samples generated from generative adversarial nets (GANs) to make the botnet detectors adept at recognising adversarial evasions. However, the synthetic evasions may not follow the original semantics of the input samples. This paper proposes a novel GAN model leveraged with deep reinforcement learning (DRL) to explore semantic aware samples and simultaneously harden its detection. A DRL agent is used to attack the discriminator of the GAN that acts as a botnet detector. The discriminator is trained on the crafted perturbations by the agent during the GAN training, which helps the GAN generator converge earlier than the case without DRL. We name this model RELEVAGAN, i.e. ["relive a GAN" or deep REinforcement Learning-based Evasion Generative Adversarial Network] because, with the help of DRL, it minimises the GAN's job by letting its generator explore the evasion samples within the semantic limits. During the GAN training, the attacks are conducted to adjust the discriminator weights for learning crafted perturbations by the agent. RELEVAGAN does not require adversarial training for the ML classifiers since it can act as an adversarial semantic-aware botnet detection model. Code will be available at https://github.com/rhr407/RELEVAGAN.
Towards On-Device AI and Blockchain for 6G enabled Agricultural Supply-chain Management
Mar 12, 2022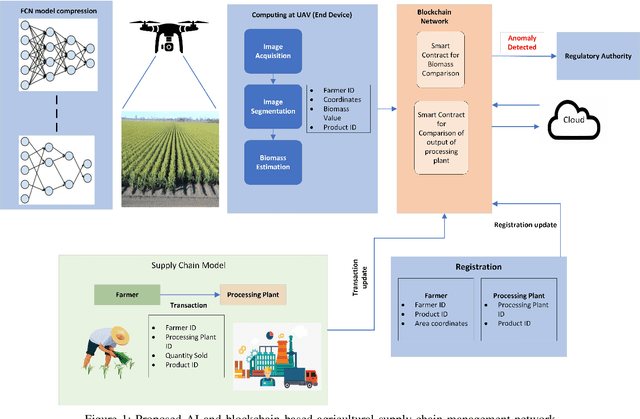
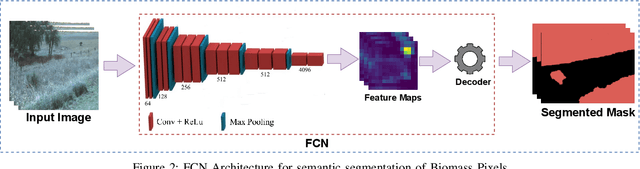
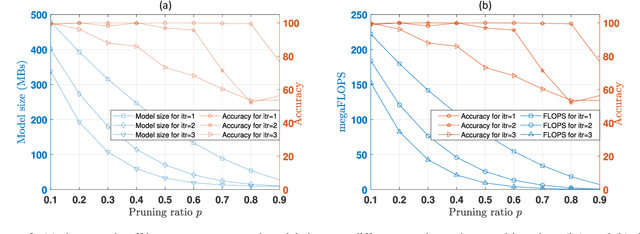
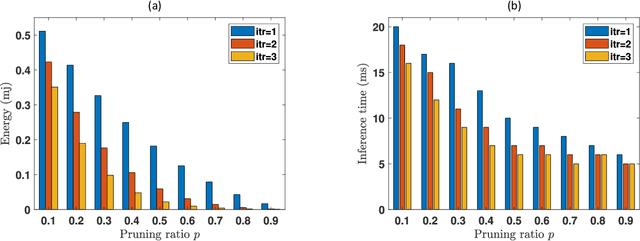
6G envisions artificial intelligence (AI) powered solutions for enhancing the quality-of-service (QoS) in the network and to ensure optimal utilization of resources. In this work, we propose an architecture based on the combination of unmanned aerial vehicles (UAVs), AI and blockchain for agricultural supply-chain management with the purpose of ensuring traceability, transparency, tracking inventories and contracts. We propose a solution to facilitate on-device AI by generating a roadmap of models with various resource-accuracy trade-offs. A fully convolutional neural network (FCN) model is used for biomass estimation through images captured by the UAV. Instead of a single compressed FCN model for deployment on UAV, we motivate the idea of iterative pruning to provide multiple task-specific models with various complexities and accuracy. To alleviate the impact of flight failure in a 6G enabled dynamic UAV network, the proposed model selection strategy will assist UAVs to update the model based on the runtime resource requirements.
Learning-Based Path Planning for Long-Range Autonomous Valet Parking
Sep 23, 2021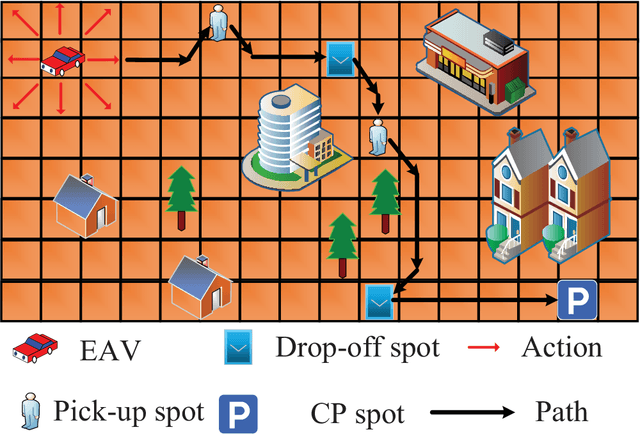
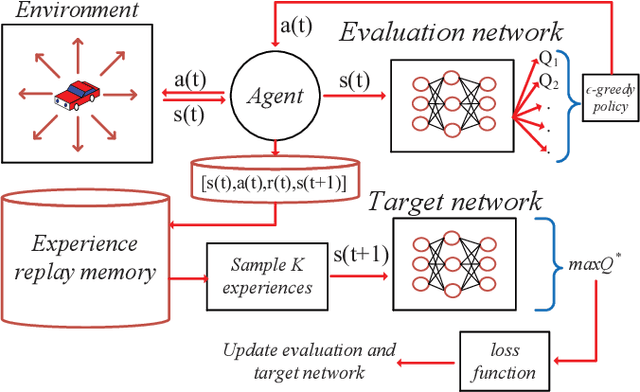
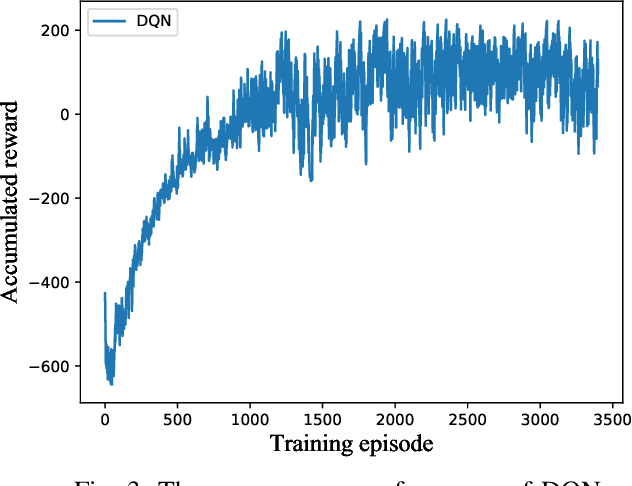

In this paper, to reduce the congestion rate at the city center and increase the quality of experience (QoE) of each user, the framework of long-range autonomous valet parking (LAVP) is presented, where an Electric Autonomous Vehicle (EAV) is deployed in the city, which can pick up, drop off users at their required spots, and then drive to the car park out of city center autonomously. In this framework, we aim to minimize the overall distance of the EAV, while guarantee all users are served, i.e., picking up, and dropping off users at their required spots through optimizing the path planning of the EAV and number of serving time slots. To this end, we first propose a learning based algorithm, which is named as Double-Layer Ant Colony Optimization (DL-ACO) algorithm to solve the above problem in an iterative way. Then, to make the real-time decision, while consider the dynamic environment (i.e., the EAV may pick up and drop off users from different locations), we further present a deep reinforcement learning (DRL) based algorithm, which is known as deep Q network (DQN). The experimental results show that the DL-ACO and DQN-based algorithms both achieve the considerable performance.
Private and Utility Enhanced Recommendations with Local Differential Privacy and Gaussian Mixture Model
Mar 06, 2021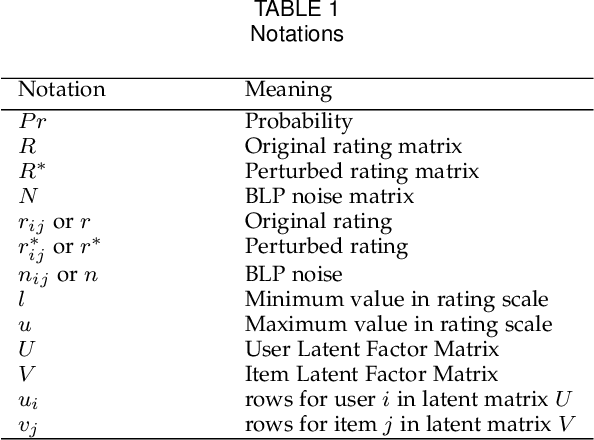
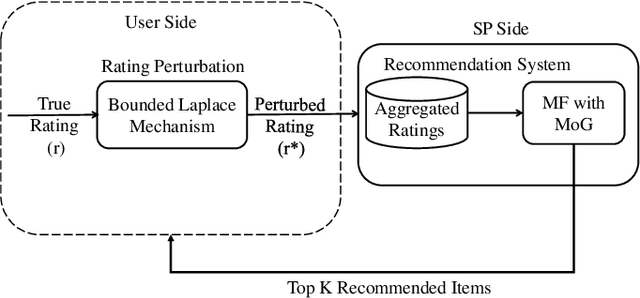
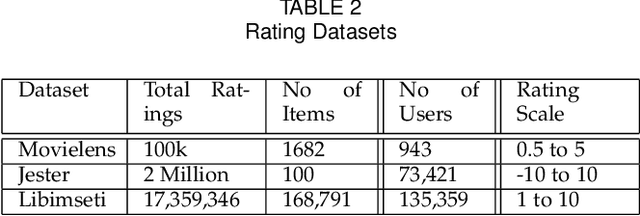
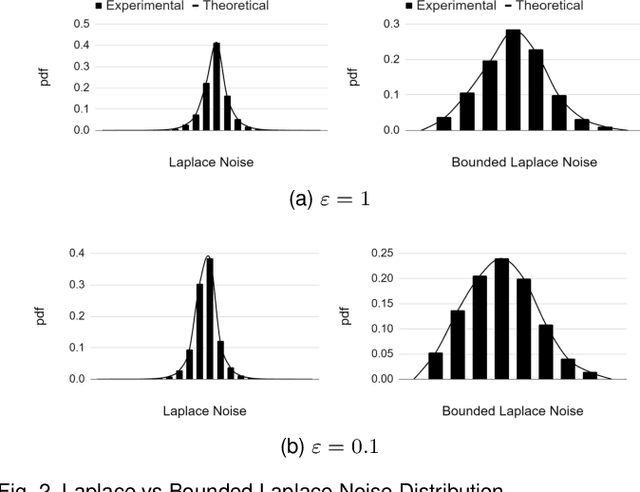
Recommendation systems rely heavily on users behavioural and preferential data (e.g. ratings, likes) to produce accurate recommendations. However, users experience privacy concerns due to unethical data aggregation and analytical practices carried out by the Service Providers (SP). Local differential privacy (LDP) based perturbation mechanisms add noise to users data at user side before sending it to the SP. The SP then uses the perturbed data to perform recommendations. Although LDP protects the privacy of users from SP, it causes a substantial decline in predictive accuracy. To address this issue, we propose an LDP-based Matrix Factorization (MF) with a Gaussian Mixture Model (MoG). The LDP perturbation mechanism, Bounded Laplace (BLP), regulates the effect of noise by confining the perturbed ratings to a predetermined domain. We derive a sufficient condition of the scale parameter for BLP to satisfy $\epsilon$ LDP. At the SP, The MoG model estimates the noise added to perturbed ratings and the MF algorithm predicts missing ratings. Our proposed LDP based recommendation system improves the recommendation accuracy without violating LDP principles. The empirical evaluations carried out on three real world datasets, i.e., Movielens, Libimseti and Jester, demonstrate that our method offers a substantial increase in predictive accuracy under strong privacy guarantee.
Multi-Agent Deep Reinforcement Learning Based Trajectory Planning for Multi-UAV Assisted Mobile Edge Computing
Sep 23, 2020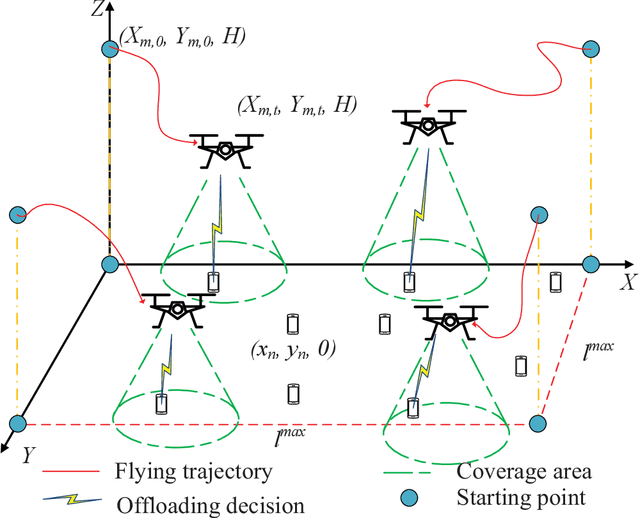
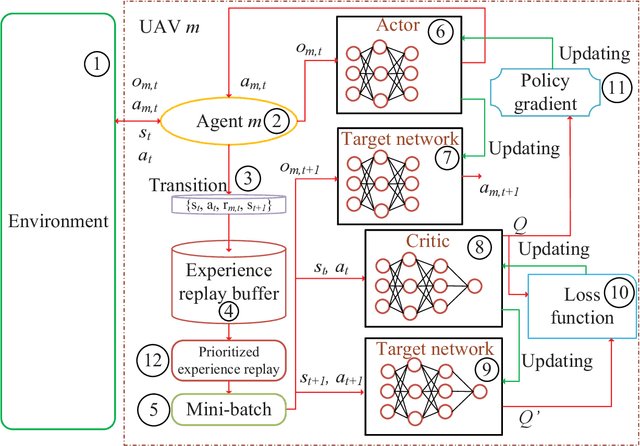

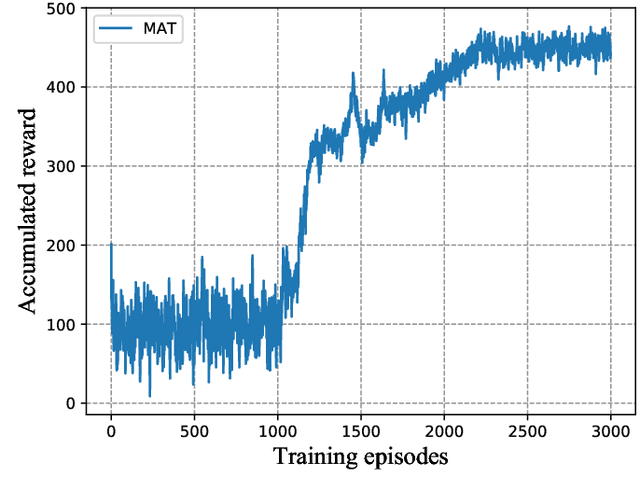
An unmanned aerial vehicle (UAV)-aided mobile edge computing (MEC) framework is proposed, where several UAVs having different trajectories fly over the target area and support the user equipments (UEs) on the ground. We aim to jointly optimize the geographical fairness among all the UEs, the fairness of each UAV' UE-load and the overall energy consumption of UEs. The above optimization problem includes both integer and continues variables and it is challenging to solve. To address the above problem, a multi-agent deep reinforcement learning based trajectory control algorithm is proposed for managing the trajectory of each UAV independently, where the popular Multi-Agent Deep Deterministic Policy Gradient (MADDPG) method is applied. Given the UAVs' trajectories, a low-complexity approach is introduced for optimizing the offloading decisions of UEs. We show that our proposed solution has considerable performance over other traditional algorithms, both in terms of the fairness for serving UEs, fairness of UE-load at each UAV and energy consumption for all the UEs.