 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Assessment with QoS Enhancement for HD Map Updates in a Vehicular Network
Paper and Code
Jul 31, 2024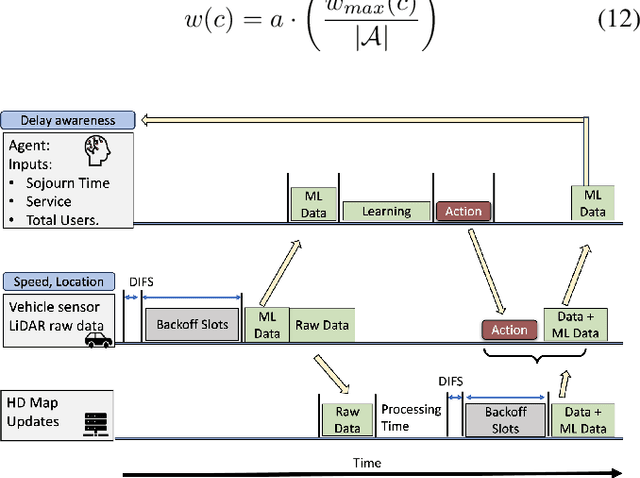
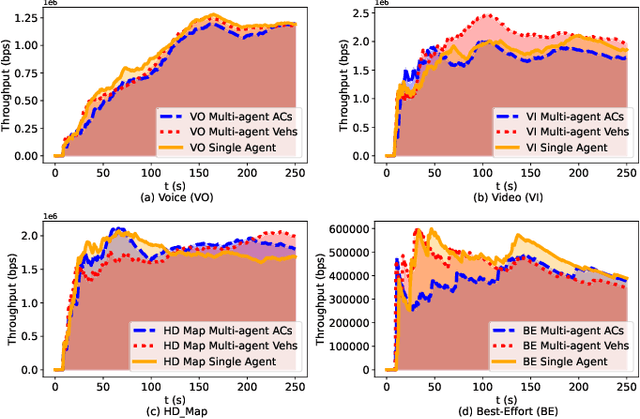
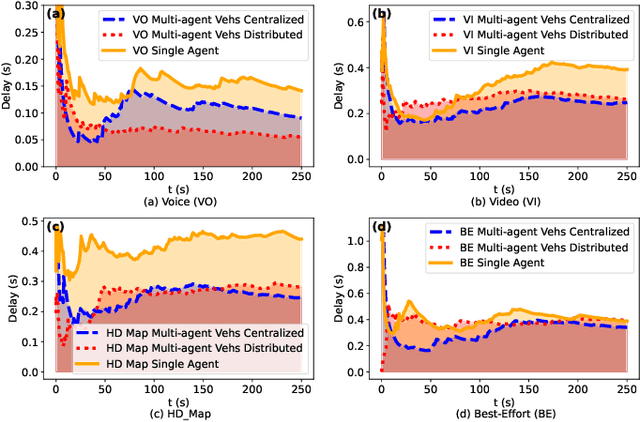
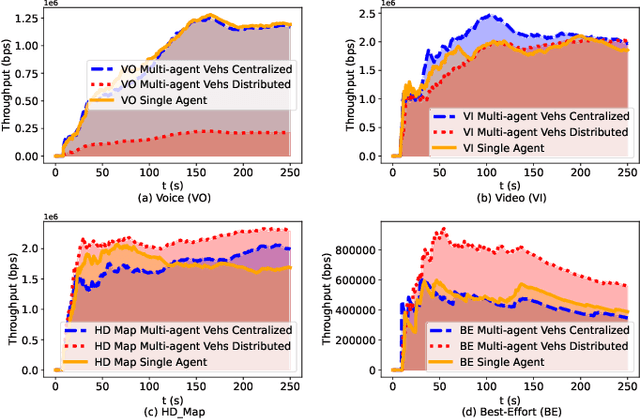
Reinforcement Learning (RL) algorithms have been used to address the challenging problems in the offloading process of vehicular ad hoc networks (VANET). More recently, they have been utilized to improve the dissemination of high-definition (HD) Maps. Nevertheless, implementing solutions such as deep Q-learning (DQN) and Actor-critic at the autonomous vehicle (AV) may lead to an increase in the computational load, causing a heavy burden on the computational devices and higher costs. Moreover, their implementation might raise compatibility issues between technologies due to the required modifications to the standards. Therefore, in this paper, we assess the scalability of an application utilizing a Q-learning single-agent solution in a distributed multi-agent environment. This application improves the network performance by taking advantage of a smaller state, and action space whilst using a multi-agent approach. The proposed solution is extensively evaluated with different test cases involving reward function considering individual or overall network performance, number of agents, and centralized and distributed learning comparison. The experimental results demonstrate that the time latencies of our proposed solution conducted in voice, video, HD Map, and best-effort cases have significant improvements, with 40.4%, 36%, 43%, and 12% respectively, compared to the performances with the single-agent approach.