 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOFA: A Framework of Initializing Unseen Subword Embeddings for Efficient Large-scale Multilingual Continued Pretraining
Paper and Code
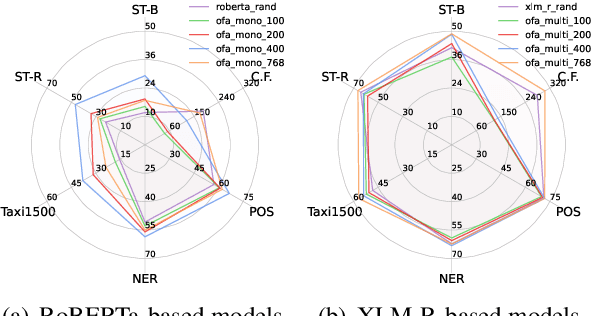
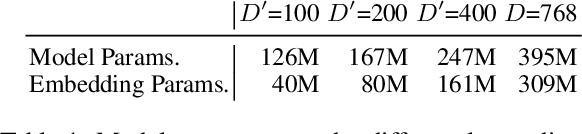
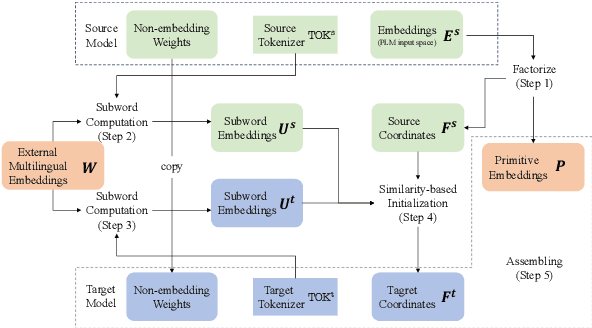
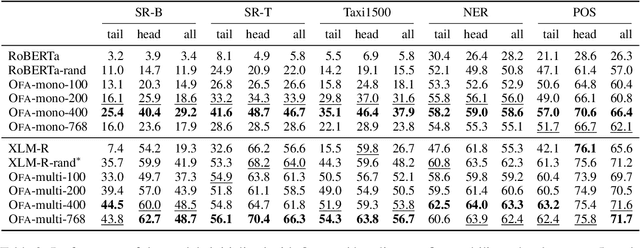
Pretraining multilingual language models from scratch requires considerable computational resources and substantial training data. Therefore, a more efficient method is to adapt existing pretrained language models (PLMs) to new languages via vocabulary extension and continued pretraining. However, this method usually randomly initializes the embeddings of new subwords and introduces substantially more embedding parameters to the language model, thus weakening the efficiency. To address these issues, we propose a novel framework: \textbf{O}ne \textbf{F}or \textbf{A}ll (\textbf{\textsc{Ofa}}), which wisely initializes the embeddings of unseen subwords from target languages and thus can adapt a PLM to multiple languages efficiently and effectively. \textsc{Ofa} takes advantage of external well-aligned multilingual word embeddings and injects the alignment knowledge into the new embeddings. In addition, \textsc{Ofa} applies matrix factorization and replaces the cumbersome embeddings with two lower-dimensional matrices, which significantly reduces the number of parameters while not sacrificing the performance. Through extensive experiments, we show models initialized by \textsc{Ofa} are efficient and outperform several baselines. \textsc{Ofa} not only accelerates the convergence of continued pretraining, which is friendly to a limited computation budget, but also improves the zero-shot crosslingual transfer on a wide range of downstream tasks. We make our code and models publicly available.