 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding In-Context Machine Translation for Low-Resource Languages: A Case Study on Manchu
Paper and Code
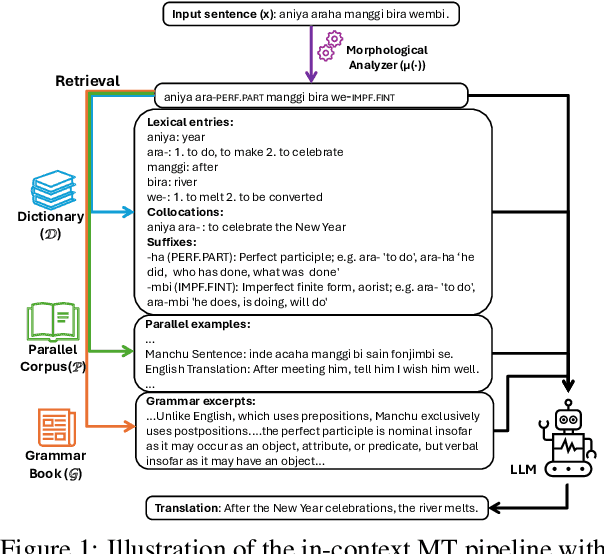
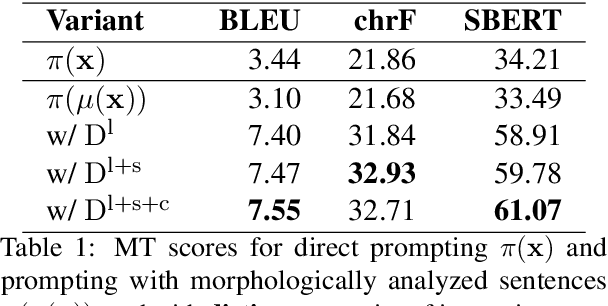
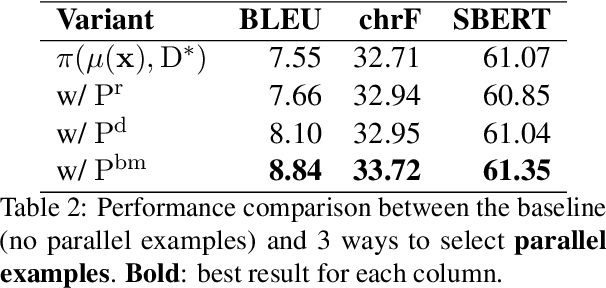
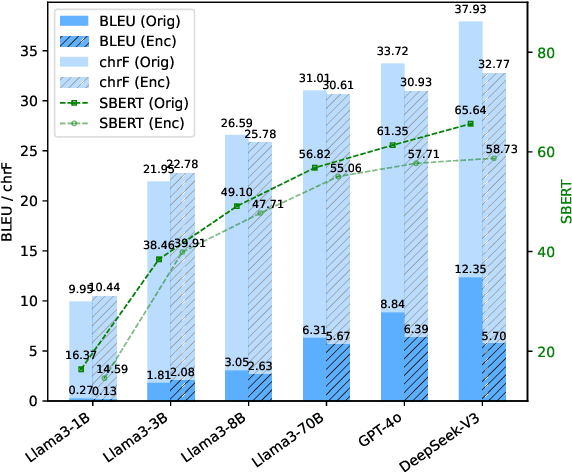
In-context machine translation (MT) with large language models (LLMs) is a promising approach for low-resource MT, as it can readily take advantage of linguistic resources such as grammar books and dictionaries. Such resources are usually selectively integrated into the prompt so that LLMs can directly perform translation without any specific training, via their in-context learning capability (ICL). However, the relative importance of each type of resource e.g., dictionary, grammar book, and retrieved parallel examples, is not entirely clear. To address this gap, this study systematically investigates how each resource and its quality affects the translation performance, with the Manchu language as our case study. To remove any prior knowledge of Manchu encoded in the LLM parameters and single out the effect of ICL, we also experiment with an encrypted version of Manchu texts. Our results indicate that high-quality dictionaries and good parallel examples are very helpful, while grammars hardly help. In a follow-up study, we showcase a promising application of in-context MT: parallel data augmentation as a way to bootstrap the conventional MT model. When monolingual data abound, generating synthetic parallel data through in-context MT offers a pathway to mitigate data scarcity and build effective and efficient low-resource neural MT systems.