 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtractBench: A Benchmark and Evaluation Methodology for Complex Structured Extraction
Feb 13, 2026Unstructured documents like PDFs contain valuable structured information, but downstream systems require this data in reliable, standardized formats. LLMs are increasingly deployed to automate this extraction, making accuracy and reliability paramount. However, progress is bottlenecked by two gaps. First, no end-to-end benchmark evaluates PDF-to-JSON extraction under enterprise-scale schema breadth. Second, no principled methodology captures the semantics of nested extraction, where fields demand different notions of correctness (exact match for identifiers, tolerance for quantities, semantic equivalence for names), arrays require alignment, and omission must be distinguished from hallucination. We address both gaps with ExtractBench, an open-source benchmark and evaluation framework for PDF-to-JSON structured extraction. The benchmark pairs 35 PDF documents with JSON Schemas and human-annotated gold labels across economically valuable domains, yielding 12,867 evaluatable fields spanning schema complexities from tens to hundreds of fields. The evaluation framework treats the schema as an executable specification: each field declares its scoring metric. Baseline evaluations reveal that frontier models (GPT-5/5.2, Gemini-3 Flash/Pro, Claude 4.5 Opus/Sonnet) remain unreliable on realistic schemas. Performance degrades sharply with schema breadth, culminating in 0% valid output on a 369-field financial reporting schema across all tested models. We release ExtractBench at https://github.com/ContextualAI/extract-bench.
Exploring the Meta-level Reasoning of Large Language Models via a Tool-based Multi-hop Tabular Question Answering Task
Jan 12, 2026Recent advancements in Large Language Models (LLMs) are increasingly focused on "reasoning" ability, a concept with many overlapping definitions in the LLM discourse. We take a more structured approach, distinguishing meta-level reasoning (denoting the process of reasoning about intermediate steps required to solve a task) from object-level reasoning (which concerns the low-level execution of the aforementioned steps.) We design a novel question answering task, which is based around the values of geopolitical indicators for various countries over various years. Questions require breaking down into intermediate steps, retrieval of data, and mathematical operations over that data. The meta-level reasoning ability of LLMs is analysed by examining the selection of appropriate tools for answering questions. To bring greater depth to the analysis of LLMs beyond final answer accuracy, our task contains 'essential actions' against which we can compare the tool call output of LLMs to infer the strength of reasoning ability. We find that LLMs demonstrate good meta-level reasoning on our task, yet are flawed in some aspects of task understanding. We find that n-shot prompting has little effect on accuracy; error messages encountered do not often deteriorate performance; and provide additional evidence for the poor numeracy of LLMs. Finally, we discuss the generalisation and limitation of our findings to other task domains.
Aligning Explainable AI and the Law: The European Perspective
Feb 22, 2023The European Union has proposed the Artificial Intelligence Act intending to regulate AI systems, especially those used in high-risk, safety-critical applications such as healthcare. Among the Act's articles are detailed requirements for transparency and explainability. The field of explainable AI (XAI) offers technologies that could address many of these requirements. However, there are significant differences between the solutions offered by XAI and the requirements of the AI Act, for instance, the lack of an explicit definition of transparency. We argue that collaboration is essential between lawyers and XAI researchers to address these differences. To establish common ground, we give an overview of XAI and its legal relevance followed by a reading of the transparency and explainability requirements of the AI Act and the related General Data Protection Regulation (GDPR). We then discuss four main topics where the differences could induce issues. Specifically, the legal status of XAI, the lack of a definition of transparency, issues around conformity assessments, and the use of XAI for dataset-related transparency. We hope that increased clarity will promote interdisciplinary research between the law and XAI and support the creation of a sustainable regulation that fosters responsible innovation.
Investigating the use of Paraphrase Generation for Question Reformulation in the FRANK QA system
Jun 06, 2022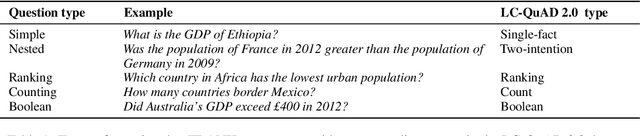
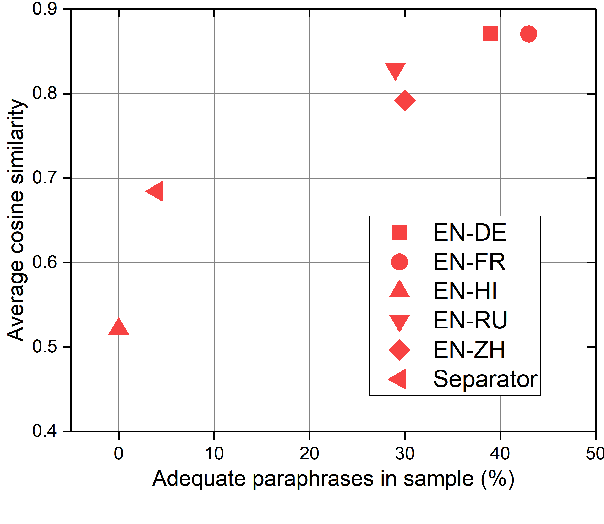

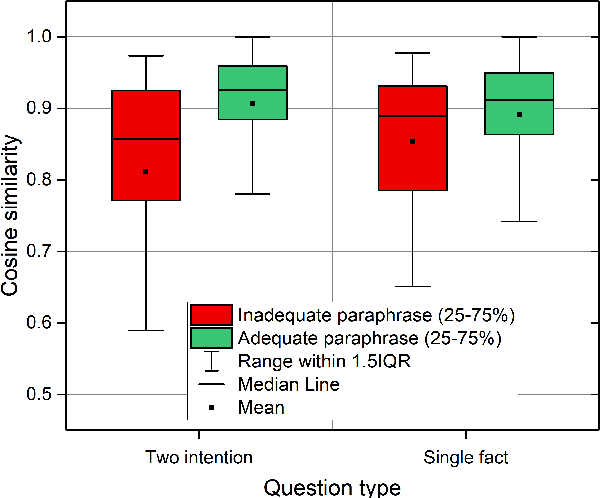
We present a study into the ability of paraphrase generation methods to increase the variety of natural language questions that the FRANK Question Answering system can answer. We first evaluate paraphrase generation methods on the LC-QuAD 2.0 dataset using both automatic metrics and human judgement, and discuss their correlation. Error analysis on the dataset is also performed using both automatic and manual approaches, and we discuss how paraphrase generation and evaluation is affected by data points which contain error. We then simulate an implementation of the best performing paraphrase generation method (an English-French backtranslation) into FRANK in order to test our original hypothesis, using a small challenge dataset. Our two main conclusions are that cleaning of LC-QuAD 2.0 is required as the errors present can affect evaluation; and that, due to limitations of FRANK's parser, paraphrase generation is not a method which we can rely on to improve the variety of natural language questions that FRANK can answer.