 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlways Keep your Target in Mind: Studying Semantics and Improving Performance of Neural Lexical Substitution
Jun 07, 2022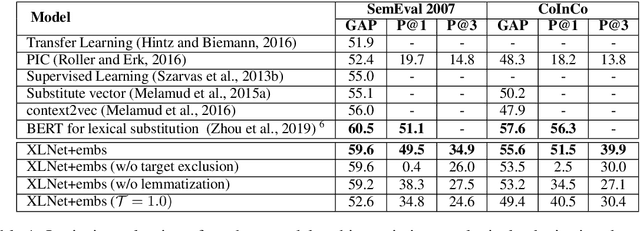
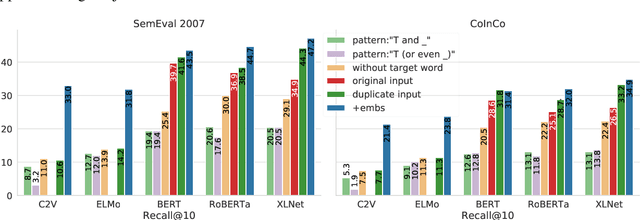
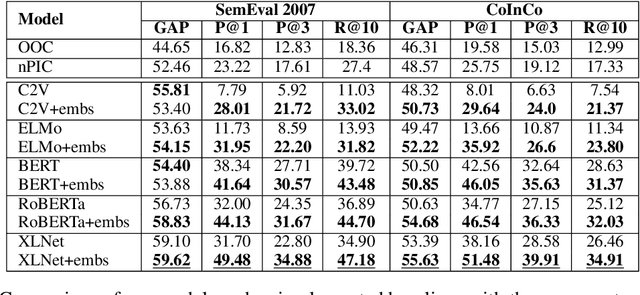
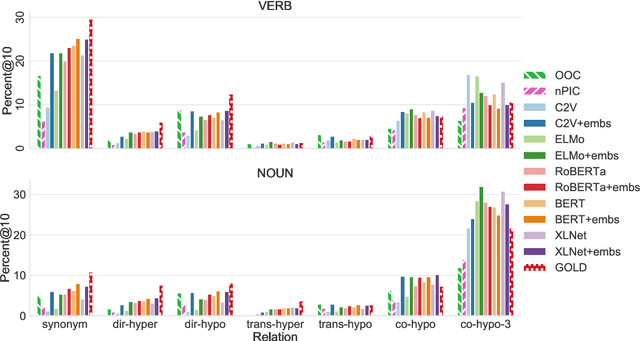
Lexical substitution, i.e. generation of plausible words that can replace a particular target word in a given context, is an extremely powerful technology that can be used as a backbone of various NLP applications, including word sense induction and disambiguation, lexical relation extraction, data augmentation, etc. In this paper, we present a large-scale comparative study of lexical substitution methods employing both rather old and most recent language and masked language models (LMs and MLMs), such as context2vec, ELMo, BERT, RoBERTa, XLNet. We show that already competitive results achieved by SOTA LMs/MLMs can be further substantially improved if information about the target word is injected properly. Several existing and new target word injection methods are compared for each LM/MLM using both intrinsic evaluation on lexical substitution datasets and extrinsic evaluation on word sense induction (WSI) datasets. On two WSI datasets we obtain new SOTA results. Besides, we analyze the types of semantic relations between target words and their substitutes generated by different models or given by annotators.
* arXiv admin note: text overlap with arXiv:2006.00031
Combining Neural Language Models for WordSense Induction
Jun 23, 2020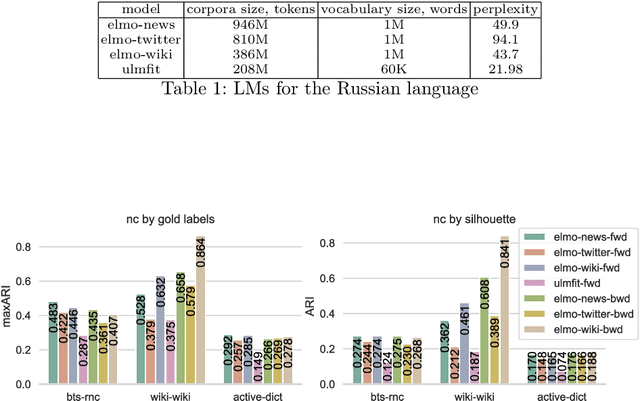
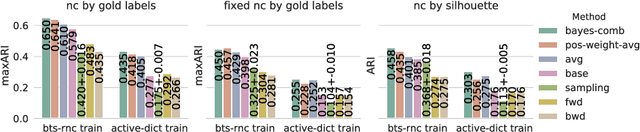
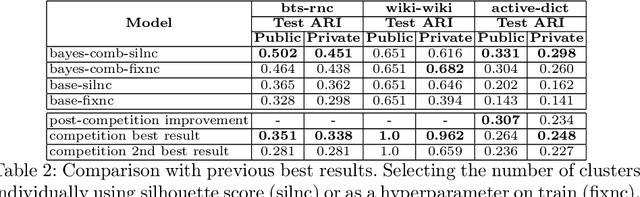
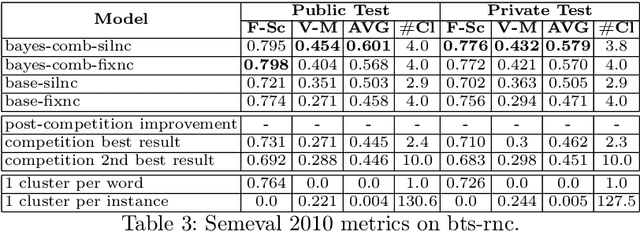
Word sense induction (WSI) is the problem of grouping occurrences of an ambiguous word according to the expressed sense of this word. Recently a new approach to this task was proposed, which generates possible substitutes for the ambiguous word in a particular context using neural language models, and then clusters sparse bag-of-words vectors built from these substitutes. In this work, we apply this approach to the Russian language and improve it in two ways. First, we propose methods of combining left and right contexts, resulting in better substitutes generated. Second, instead of fixed number of clusters for all ambiguous words we propose a technique for selecting individual number of clusters for each word. Our approach established new state-of-the-art level, improving current best results of WSI for the Russian language on two RUSSE 2018 datasets by a large margin.
* International Conference on Analysis of Images, Social Networks and Texts AIST 2019: Analysis of Images, Social Networks and Texts, pp 105-121
A Comparative Study of Lexical Substitution Approaches based on Neural Language Models
May 29, 2020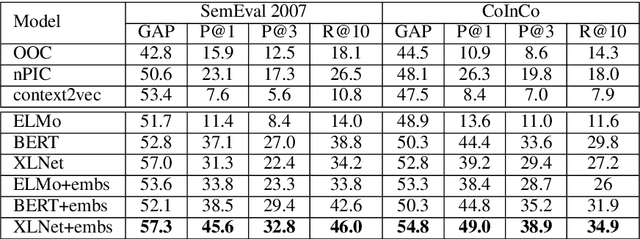
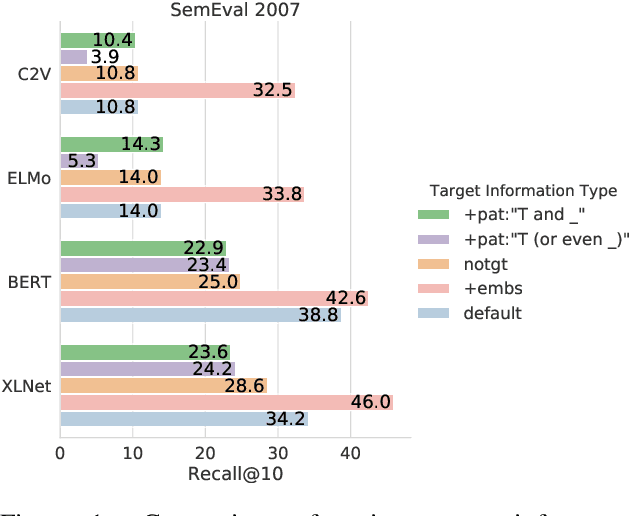
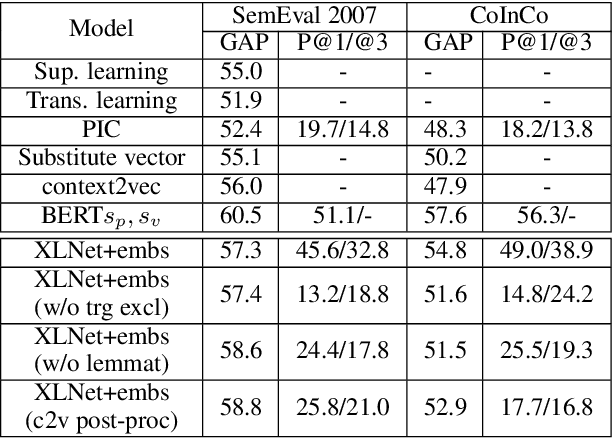
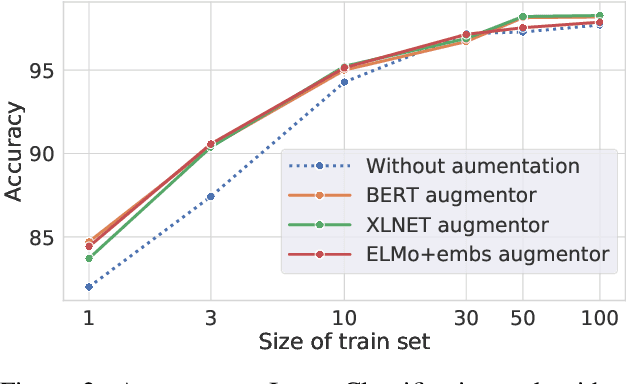
Lexical substitution in context is an extremely powerful technology that can be used as a backbone of various NLP applications, such as word sense induction, lexical relation extraction, data augmentation, etc. In this paper, we present a large-scale comparative study of popular neural language and masked language models (LMs and MLMs), such as context2vec, ELMo, BERT, XLNet, applied to the task of lexical substitution. We show that already competitive results achieved by SOTA LMs/MLMs can be further improved if information about the target word is injected properly, and compare several target injection methods. In addition, we provide analysis of the types of semantic relations between the target and substitutes generated by different models providing insights into what kind of words are really generated or given by annotators as substitutes.