 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlways Keep your Target in Mind: Studying Semantics and Improving Performance of Neural Lexical Substitution
Paper and Code
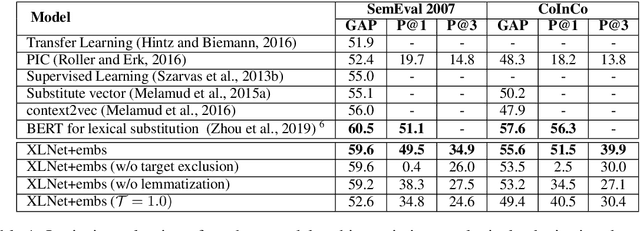
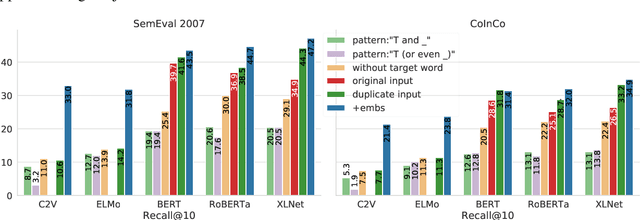
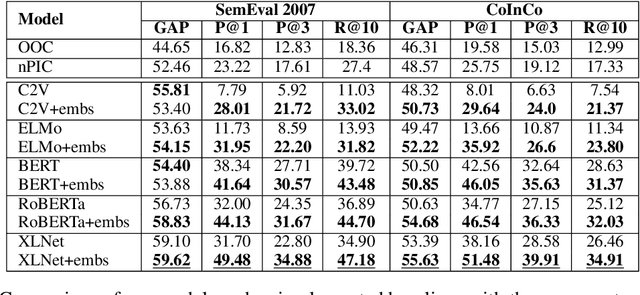
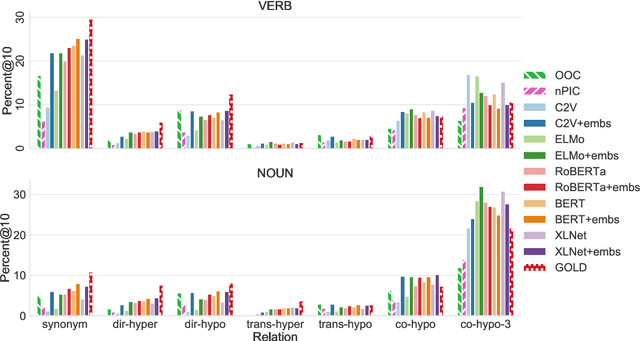
Lexical substitution, i.e. generation of plausible words that can replace a particular target word in a given context, is an extremely powerful technology that can be used as a backbone of various NLP applications, including word sense induction and disambiguation, lexical relation extraction, data augmentation, etc. In this paper, we present a large-scale comparative study of lexical substitution methods employing both rather old and most recent language and masked language models (LMs and MLMs), such as context2vec, ELMo, BERT, RoBERTa, XLNet. We show that already competitive results achieved by SOTA LMs/MLMs can be further substantially improved if information about the target word is injected properly. Several existing and new target word injection methods are compared for each LM/MLM using both intrinsic evaluation on lexical substitution datasets and extrinsic evaluation on word sense induction (WSI) datasets. On two WSI datasets we obtain new SOTA results. Besides, we analyze the types of semantic relations between target words and their substitutes generated by different models or given by annotators.