 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Lexical Substitution Approaches based on Neural Language Models
Paper and Code
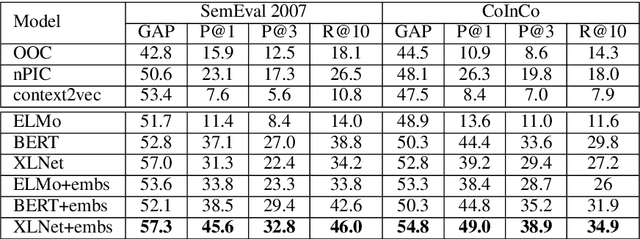
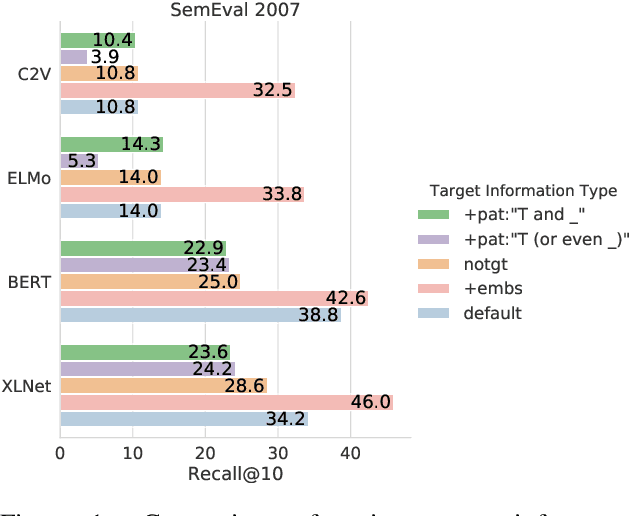
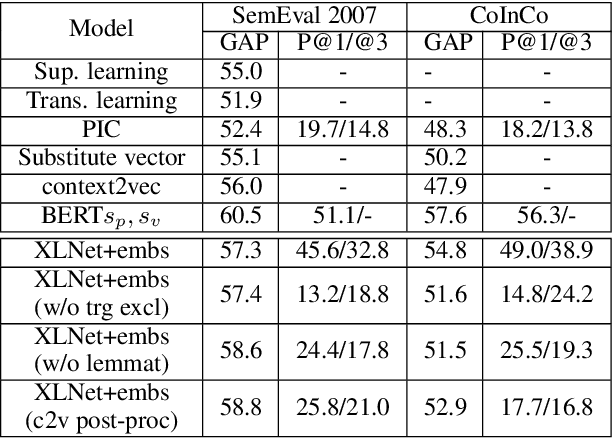
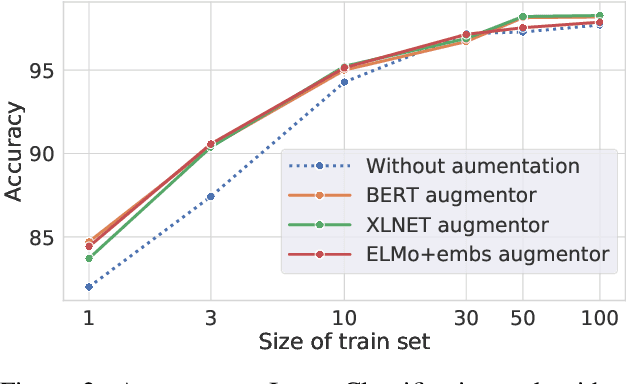
Lexical substitution in context is an extremely powerful technology that can be used as a backbone of various NLP applications, such as word sense induction, lexical relation extraction, data augmentation, etc. In this paper, we present a large-scale comparative study of popular neural language and masked language models (LMs and MLMs), such as context2vec, ELMo, BERT, XLNet, applied to the task of lexical substitution. We show that already competitive results achieved by SOTA LMs/MLMs can be further improved if information about the target word is injected properly, and compare several target injection methods. In addition, we provide analysis of the types of semantic relations between the target and substitutes generated by different models providing insights into what kind of words are really generated or given by annotators as substitutes.