 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdLoCo: adaptive batching significantly improves communications efficiency and convergence for Large Language Models
Aug 25, 2025Scaling distributed training of Large Language Models (LLMs) requires not only algorithmic advances but also efficient utilization of heterogeneous hardware resources. While existing methods such as DiLoCo have demonstrated promising results, they often fail to fully exploit computational clusters under dynamic workloads. To address this limitation, we propose a three-stage method that combines Multi-Instance Training (MIT), Adaptive Batched DiLoCo, and switch mode mechanism. MIT allows individual nodes to run multiple lightweight training streams with different model instances in parallel and merge them to combine knowledge, increasing throughput and reducing idle time. Adaptive Batched DiLoCo dynamically adjusts local batch sizes to balance computation and communication, substantially lowering synchronization delays. Switch mode further stabilizes training by seamlessly introducing gradient accumulation once adaptive batch sizes grow beyond hardware-friendly limits. Together, these innovations improve both convergence speed and system efficiency. We also provide a theoretical estimate of the number of communications required for the full convergence of a model trained using our method.
KompeteAI: Accelerated Autonomous Multi-Agent System for End-to-End Pipeline Generation for Machine Learning Problems
Aug 13, 2025



Recent Large Language Model (LLM)-based AutoML systems demonstrate impressive capabilities but face significant limitations such as constrained exploration strategies and a severe execution bottleneck. Exploration is hindered by one-shot methods lacking diversity and Monte Carlo Tree Search (MCTS) approaches that fail to recombine strong partial solutions. The execution bottleneck arises from lengthy code validation cycles that stifle iterative refinement. To overcome these challenges, we introduce KompeteAI, a novel AutoML framework with dynamic solution space exploration. Unlike previous MCTS methods that treat ideas in isolation, KompeteAI introduces a merging stage that composes top candidates. We further expand the hypothesis space by integrating Retrieval-Augmented Generation (RAG), sourcing ideas from Kaggle notebooks and arXiv papers to incorporate real-world strategies. KompeteAI also addresses the execution bottleneck via a predictive scoring model and an accelerated debugging method, assessing solution potential using early stage metrics to avoid costly full-code execution. This approach accelerates pipeline evaluation 6.9 times. KompeteAI outperforms leading methods (e.g., RD-agent, AIDE, and Ml-Master) by an average of 3\% on the primary AutoML benchmark, MLE-Bench. Additionally, we propose Kompete-bench to address limitations in MLE-Bench, where KompeteAI also achieves state-of-the-art results
Exploring Applications of State Space Models and Advanced Training Techniques in Sequential Recommendations: A Comparative Study on Efficiency and Performance
Aug 10, 2024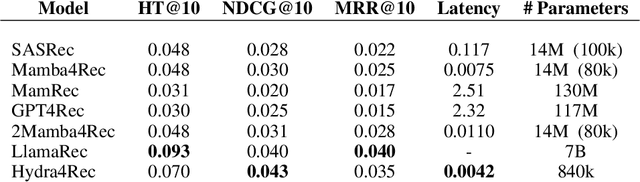
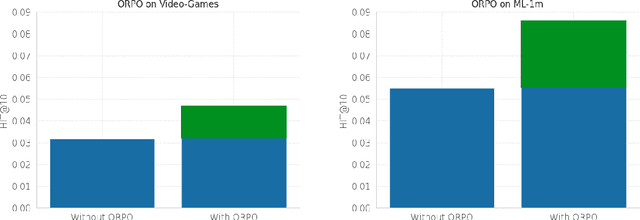
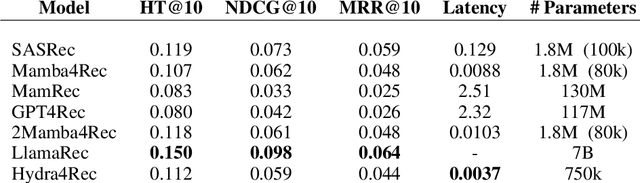
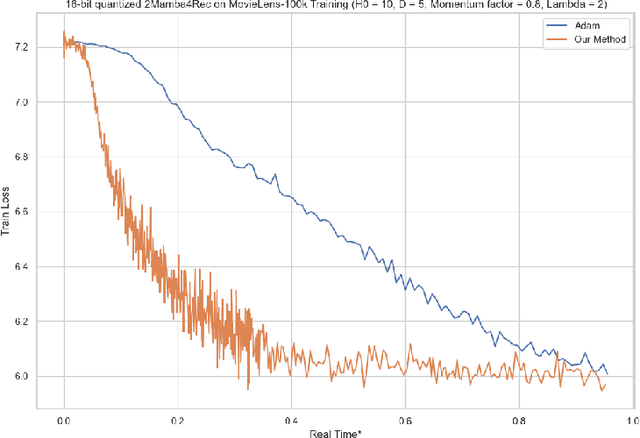
Recommender systems aim to estimate the dynamically changing user preferences and sequential dependencies between historical user behaviour and metadata. Although transformer-based models have proven to be effective in sequential recommendations, their state growth is proportional to the length of the sequence that is being processed, which makes them expensive in terms of memory and inference costs. Our research focused on three promising directions in sequential recommendations: enhancing speed through the use of State Space Models (SSM), as they can achieve SOTA results in the sequential recommendations domain with lower latency, memory, and inference costs, as proposed by arXiv:2403.03900 improving the quality of recommendations with Large Language Models (LLMs) via Monolithic Preference Optimization without Reference Model (ORPO); and implementing adaptive batch- and step-size algorithms to reduce costs and accelerate training processes.