 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Mimic Attack: Knowledge Distillation for Provably Transferable Adversarial Examples
Paper and Code
Oct 21, 2024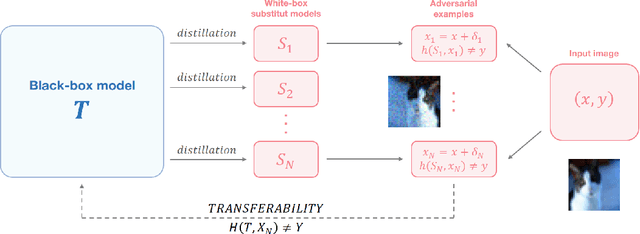
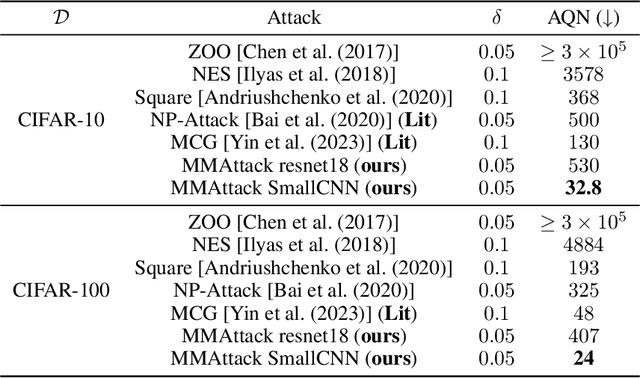
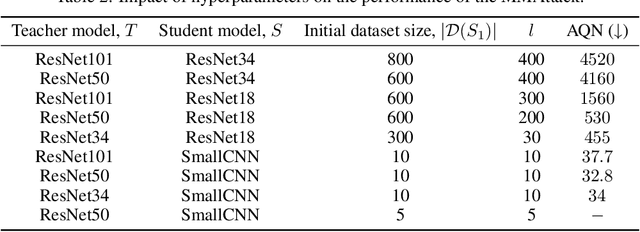
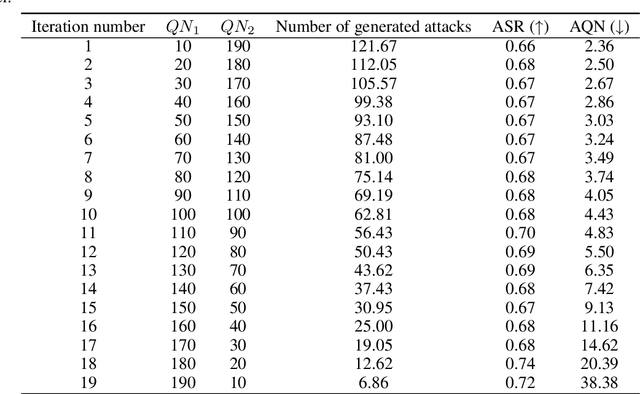
The vulnerability of artificial neural networks to adversarial perturbations in the black-box setting is widely studied in the literature. The majority of attack methods to construct these perturbations suffer from an impractically large number of queries required to find an adversarial example. In this work, we focus on knowledge distillation as an approach to conduct transfer-based black-box adversarial attacks and propose an iterative training of the surrogate model on an expanding dataset. This work is the first, to our knowledge, to provide provable guarantees on the success of knowledge distillation-based attack on classification neural networks: we prove that if the student model has enough learning capabilities, the attack on the teacher model is guaranteed to be found within the finite number of distillation iterations.