 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the computational complexity of the probabilistic label tree algorithms
Jun 01, 2019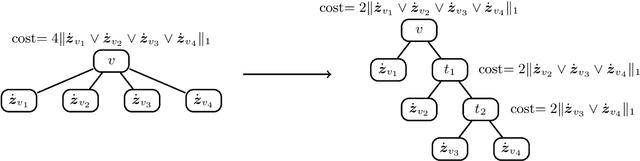
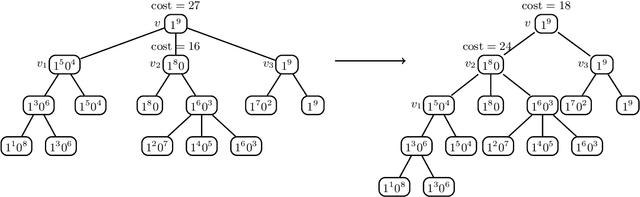


Label tree-based algorithms are widely used to tackle multi-class and multi-label problems with a large number of labels. We focus on a particular subclass of these algorithms that use probabilistic classifiers in the tree nodes. Examples of such algorithms are hierarchical softmax (HSM), designed for multi-class classification, and probabilistic label trees (PLTs) that generalize HSM to multi-label problems. If the tree structure is given, learning of PLT can be solved with provable regret guaranties [Wydmuch et.al. 2018]. However, to find a tree structure that results in a PLT with a low training and prediction computational costs as well as low statistical error seems to be a very challenging problem, not well-understood yet. In this paper, we address the problem of finding a tree structure that has low computational cost. First, we show that finding a tree with optimal training cost is NP-complete, nevertheless there are some tractable special cases with either perfect approximation or exact solution that can be obtained in linear time in terms of the number of labels $m$. For the general case, we obtain $O(\log m)$ approximation in linear time too. Moreover, we prove an upper bound on the expected prediction cost expressed in terms of the expected training cost. We also show that under additional assumptions the prediction cost of a PLT is $O(\log m)$.
A no-regret generalization of hierarchical softmax to extreme multi-label classification
Oct 27, 2018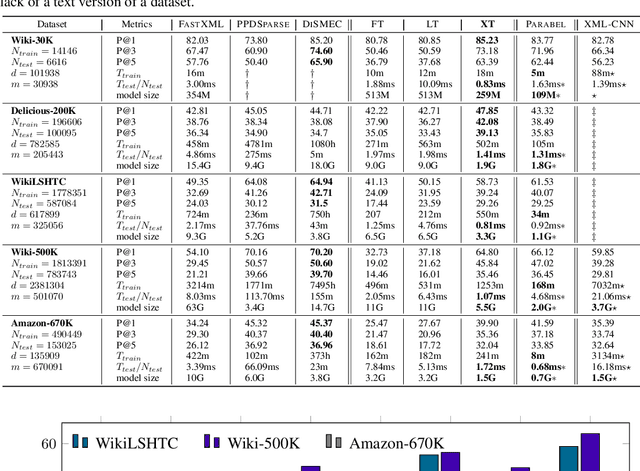
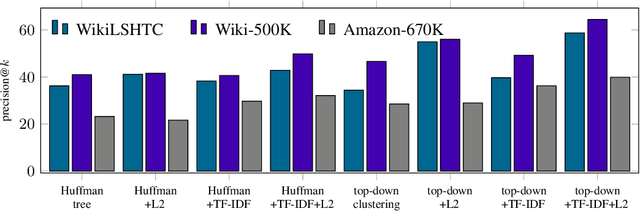
Extreme multi-label classification (XMLC) is a problem of tagging an instance with a small subset of relevant labels chosen from an extremely large pool of possible labels. Large label spaces can be efficiently handled by organizing labels as a tree, like in the hierarchical softmax (HSM) approach commonly used for multi-class problems. In this paper, we investigate probabilistic label trees (PLTs) that have been recently devised for tackling XMLC problems. We show that PLTs are a no-regret multi-label generalization of HSM when precision@k is used as a model evaluation metric. Critically, we prove that pick-one-label heuristic - a reduction technique from multi-label to multi-class that is routinely used along with HSM - is not consistent in general. We also show that our implementation of PLTs, referred to as extremeText (XT), obtains significantly better results than HSM with the pick-one-label heuristic and XML-CNN, a deep network specifically designed for XMLC problems. Moreover, XT is competitive to many state-of-the-art approaches in terms of statistical performance, model size and prediction time which makes it amenable to deploy in an online system.
Log-time and Log-space Extreme Classification
Nov 07, 2016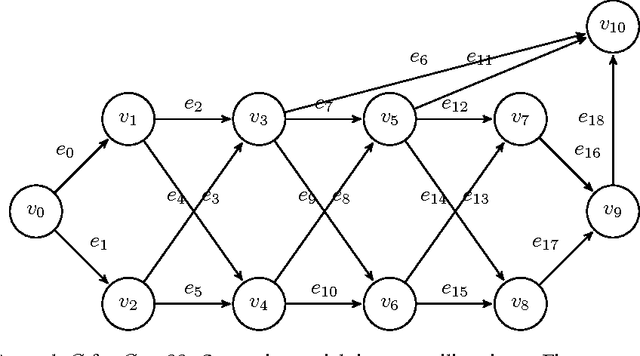
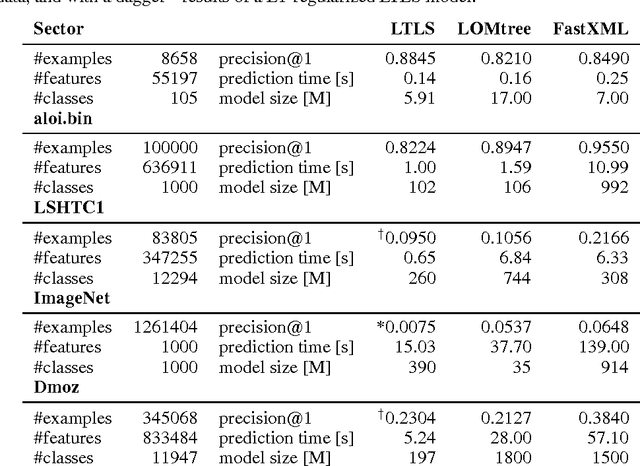
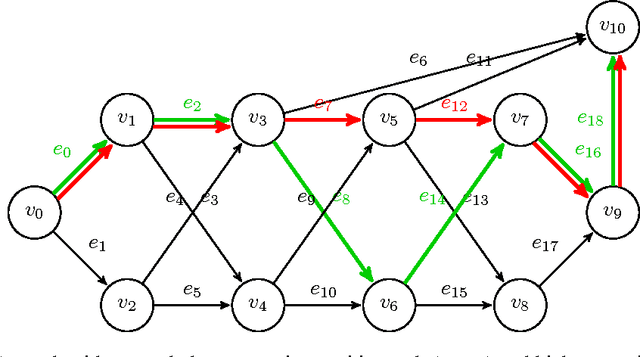
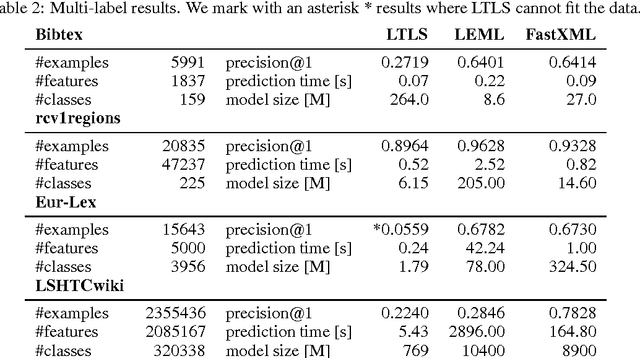
We present LTLS, a technique for multiclass and multilabel prediction that can perform training and inference in logarithmic time and space. LTLS embeds large classification problems into simple structured prediction problems and relies on efficient dynamic programming algorithms for inference. We train LTLS with stochastic gradient descent on a number of multiclass and multilabel datasets and show that despite its small memory footprint it is often competitive with existing approaches.