 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally robust self-supervised learning for tabular data
Paper and Code
Oct 11, 2024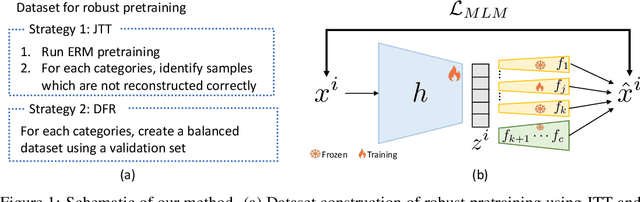
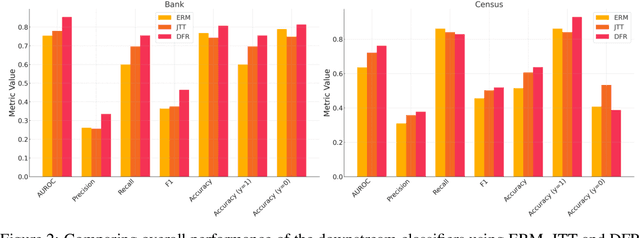
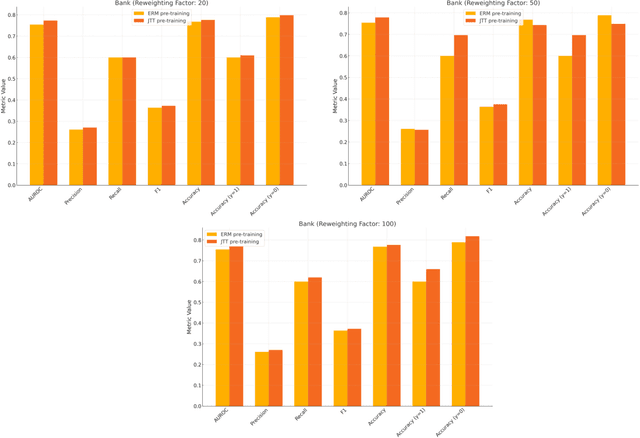
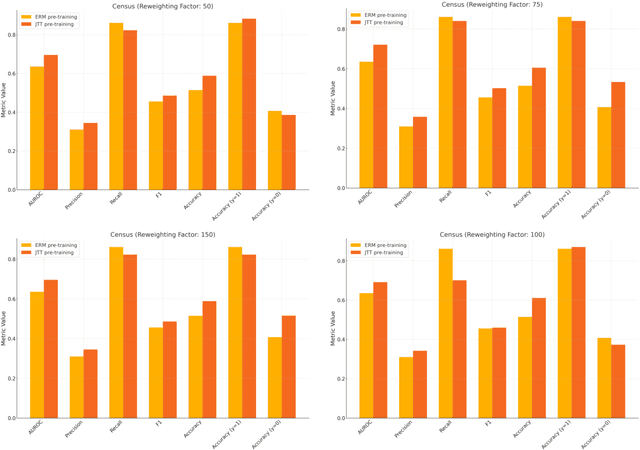
Machine learning (ML) models trained using Empirical Risk Minimization (ERM) often exhibit systematic errors on specific subpopulations of tabular data, known as error slices. Learning robust representation in presence of error slices is challenging, especially in self-supervised settings during the feature reconstruction phase, due to high cardinality features and the complexity of constructing error sets. Traditional robust representation learning methods are largely focused on improving worst group performance in supervised setting in computer vision, leaving a gap in approaches tailored for tabular data. We address this gap by developing a framework to learn robust representation in tabular data during self-supervised pre-training. Our approach utilizes an encoder-decoder model trained with Masked Language Modeling (MLM) loss to learn robust latent representations. This paper applies the Just Train Twice (JTT) and Deep Feature Reweighting (DFR) methods during the pre-training phase for tabular data. These methods fine-tune the ERM pre-trained model by up-weighting error-prone samples or creating balanced datasets for specific categorical features. This results in specialized models for each feature, which are then used in an ensemble approach to enhance downstream classification performance. This methodology improves robustness across slices, thus enhancing overall generalization performance. Extensive experiments across various datasets demonstrate the efficacy of our approach.