Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottleNet: A Deep Learning Architecture for Intelligent Mobile Cloud Computing Services
Paper and Code
Feb 04, 2019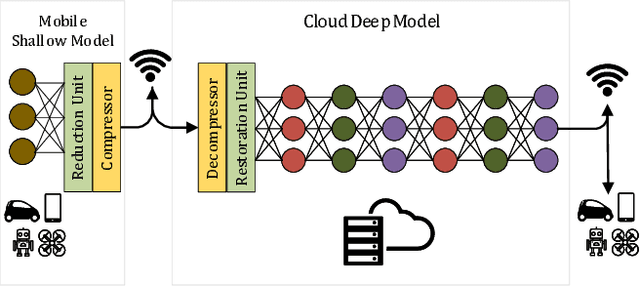

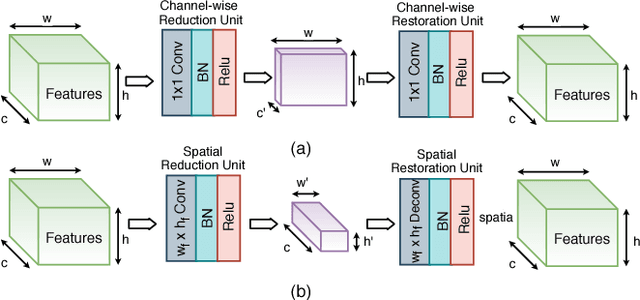

Recent studies have shown the latency and energy consumption of deep neural networks can be significantly improved by splitting the network between the mobile device and cloud. This paper introduces a new deep learning architecture, called BottleNet, for reducing the feature size needed to be sent to the cloud. Furthermore, we propose a training method for compensating for the potential accuracy loss due to the lossy compression of features before transmitting them to the cloud. BottleNet achieves on average 30x improvement in end-to-end latency and 40x improvement in mobile energy consumption compared to the cloud-only approach with negligible accuracy loss.
* arXiv admin note: text overlap with arXiv:1902.00147
View paper on