Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRun-time Deep Model Multiplexing
Paper and Code
Jan 14, 2020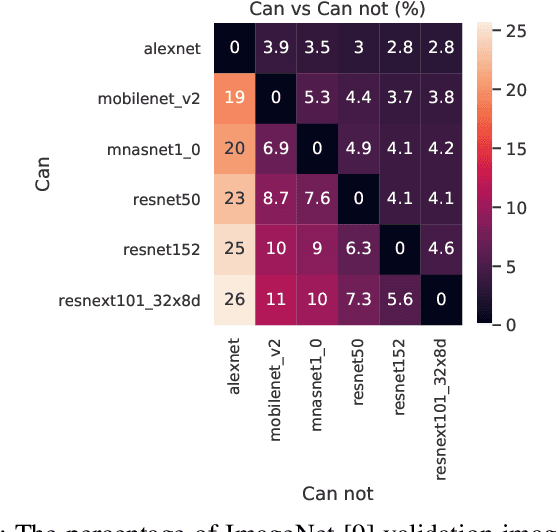
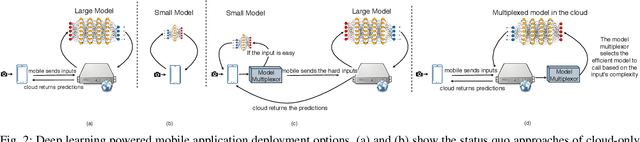


We propose a framework to design a light-weight neural multiplexer that given input and resource budgets, decides upon the appropriate model to be called for the inference. Mobile devices can use this framework to offload the hard inputs to the cloud while inferring the easy ones locally. Besides, in the large scale cloud-based intelligent applications, instead of replicating the most-accurate model, a range of small and large models can be multiplexed from depending on the input's complexity and resource budgets. Our experimental results demonstrate the effectiveness of our framework benefiting both mobile users and cloud providers.
View paper on