 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionLite: Towards Efficient Self-Attention Models for Vision
Paper and Code
Dec 21, 2020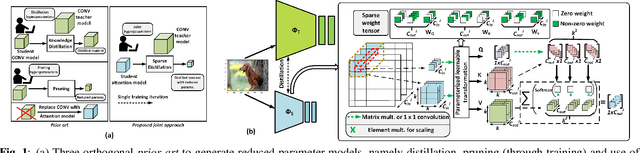
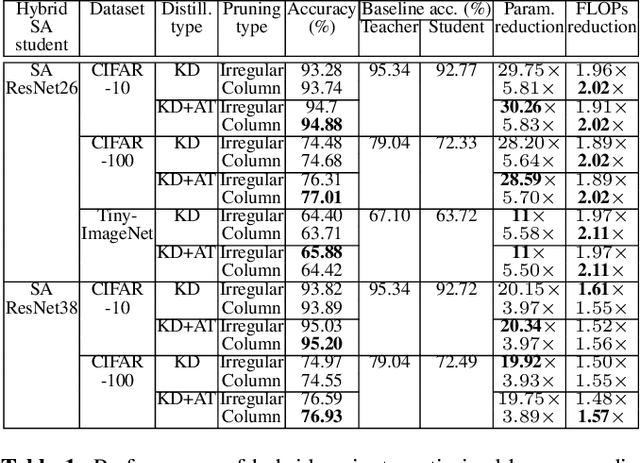
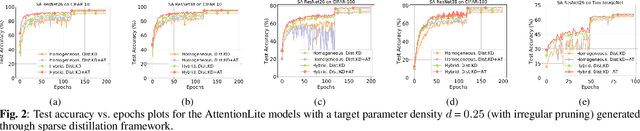
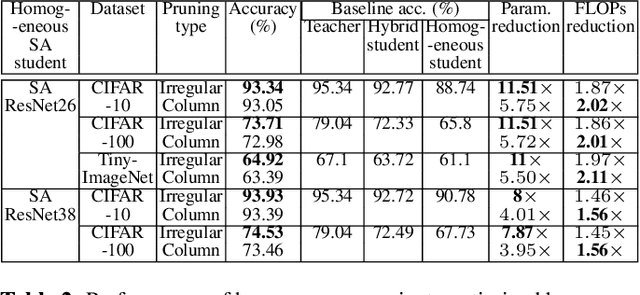
We propose a novel framework for producing a class of parameter and compute efficient models called AttentionLitesuitable for resource-constrained applications. Prior work has primarily focused on optimizing models either via knowledge distillation or pruning. In addition to fusing these two mechanisms, our joint optimization framework also leverages recent advances in self-attention as a substitute for convolutions. We can simultaneously distill knowledge from a compute-heavy teacher while also pruning the student model in a single pass of training thereby reducing training and fine-tuning times considerably. We evaluate the merits of our proposed approach on the CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets. Not only do our AttentionLite models significantly outperform their unoptimized counterparts in accuracy, we find that in some cases, that they perform almost as well as their compute-heavy teachers while consuming only a fraction of the parameters and FLOPs. Concretely, AttentionLite models can achieve upto30x parameter efficiency and 2x computation efficiency with no significant accuracy drop compared to their teacher.