 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Image Upsampling
Paper and Code
Dec 17, 2020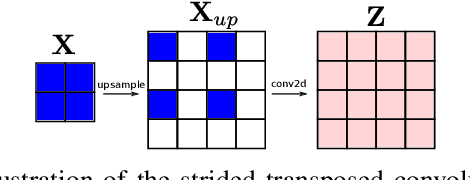
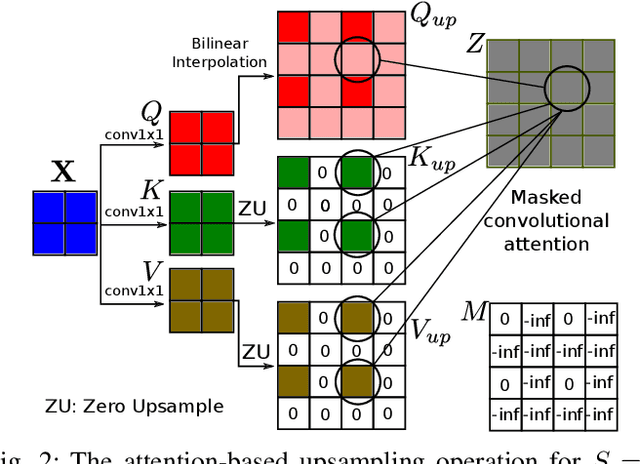
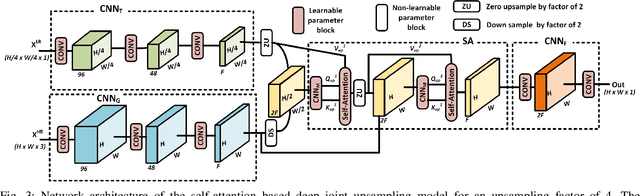

Convolutional layers are an integral part of many deep neural network solutions in computer vision. Recent work shows that replacing the standard convolution operation with mechanisms based on self-attention leads to improved performance on image classification and object detection tasks. In this work, we show how attention mechanisms can be used to replace another canonical operation: strided transposed convolution. We term our novel attention-based operation attention-based upsampling since it increases/upsamples the spatial dimensions of the feature maps. Through experiments on single image super-resolution and joint-image upsampling tasks, we show that attention-based upsampling consistently outperforms traditional upsampling methods based on strided transposed convolution or based on adaptive filters while using fewer parameters. We show that the inherent flexibility of the attention mechanism, which allows it to use separate sources for calculating the attention coefficients and the attention targets, makes attention-based upsampling a natural choice when fusing information from multiple image modalities.