 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast and Efficient Conditional Learning for Tunable Trade-Off between Accuracy and Robustness
Paper and Code
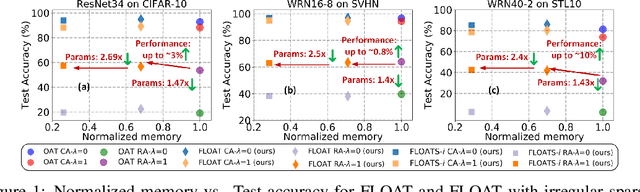

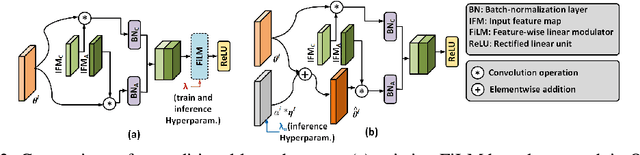
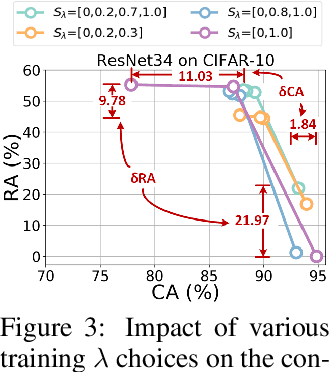
Existing models that achieve state-of-the-art (SOTA) performance on both clean and adversarially-perturbed images rely on convolution operations conditioned with feature-wise linear modulation (FiLM) layers. These layers require many new parameters and are hyperparameter sensitive. They significantly increase training time, memory cost, and potential latency which can prove costly for resource-limited or real-time applications. In this paper, we present a fast learnable once-for-all adversarial training (FLOAT) algorithm, which instead of the existing FiLM-based conditioning, presents a unique weight conditioned learning that requires no additional layer, thereby incurring no significant increase in parameter count, training time, or network latency compared to standard adversarial training. In particular, we add configurable scaled noise to the weight tensors that enables a trade-off between clean and adversarial performance. Extensive experiments show that FLOAT can yield SOTA performance improving both clean and perturbed image classification by up to ~6% and ~10%, respectively. Moreover, real hardware measurement shows that FLOAT can reduce the training time by up to 1.43x with fewer model parameters of up to 1.47x on iso-hyperparameter settings compared to the FiLM-based alternatives. Additionally, to further improve memory efficiency we introduce FLOAT sparse (FLOATS), a form of non-iterative model pruning and provide detailed empirical analysis to provide a three way accuracy-robustness-complexity trade-off for these new class of pruned conditionally trained models.