 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlanted Stixels: Representing San Francisco's Steepest Streets
Paper and Code

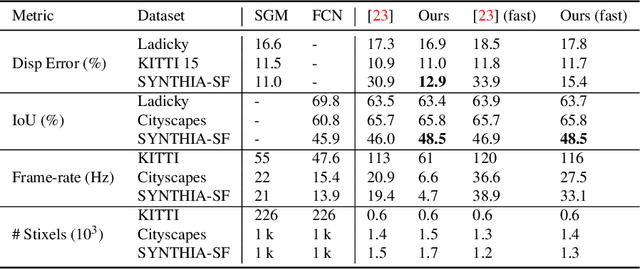
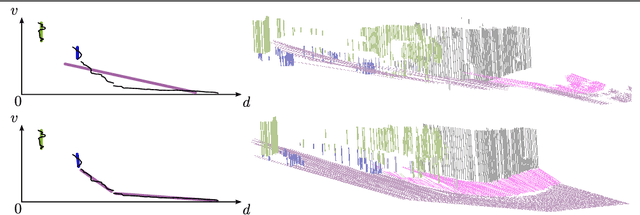
In this work we present a novel compact scene representation based on Stixels that infers geometric and semantic information. Our approach overcomes the previous rather restrictive geometric assumptions for Stixels by introducing a novel depth model to account for non-flat roads and slanted objects. Both semantic and depth cues are used jointly to infer the scene representation in a sound global energy minimization formulation. Furthermore, a novel approximation scheme is introduced that uses an extremely efficient over-segmentation. In doing so, the computational complexity of the Stixel inference algorithm is reduced significantly, achieving real-time computation capabilities with only a slight drop in accuracy. We evaluate the proposed approach in terms of semantic and geometric accuracy as well as run-time on four publicly available benchmark datasets. Our approach maintains accuracy on flat road scene datasets while improving substantially on a novel non-flat road dataset.