 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Calibration of Uncertainty Estimation in LiDAR-based Semantic Segmentation
Paper and Code
Aug 04, 2023

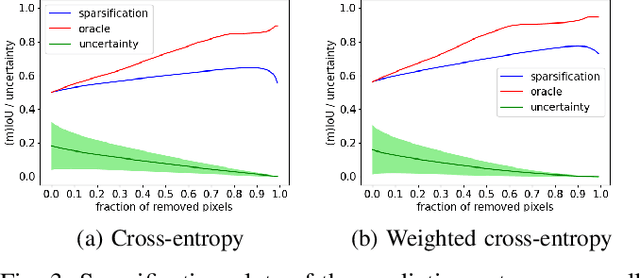

The confidence calibration of deep learning-based perception models plays a crucial role in their reliability. Especially in the context of autonomous driving, downstream tasks like prediction and planning depend on accurate confidence estimates. In point-wise multiclass classification tasks like sematic segmentation the model has to deal with heavy class imbalances. Due to their underrepresentation, the confidence calibration of classes with smaller instances is challenging but essential, not only for safety reasons. We propose a metric to measure the confidence calibration quality of a semantic segmentation model with respect to individual classes. It is calculated by computing sparsification curves for each class based on the uncertainty estimates. We use the classification calibration metric to evaluate uncertainty estimation methods with respect to their confidence calibration of underrepresented classes. We furthermore suggest a double use for the method to automatically find label problems to improve the quality of hand- or auto-annotated datasets.