 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-independent detection of known anomalies
Jul 03, 2024



One persistent obstacle in industrial quality inspection is the detection of anomalies. In real-world use cases, two problems must be addressed: anomalous data is sparse and the same types of anomalies need to be detected on previously unseen objects. Current anomaly detection approaches can be trained with sparse nominal data, whereas domain generalization approaches enable detecting objects in previously unseen domains. Utilizing those two observations, we introduce the hybrid task of domain generalization on sparse classes. To introduce an accompanying dataset for this task, we present a modification of the well-established MVTec AD dataset by generating three new datasets. In addition to applying existing methods for benchmark, we design two embedding-based approaches, Spatial Embedding MLP (SEMLP) and Labeled PatchCore. Overall, SEMLP achieves the best performance with an average image-level AUROC of 87.2 % vs. 80.4 % by MIRO. The new and openly available datasets allow for further research to improve industrial anomaly detection.
Position: Quo Vadis, Unsupervised Time Series Anomaly Detection?
May 12, 2024



The current state of machine learning scholarship in Timeseries Anomaly Detection (TAD) is plagued by the persistent use of flawed evaluation metrics, inconsistent benchmarking practices, and a lack of proper justification for the choices made in novel deep learning-based model designs. Our paper presents a critical analysis of the status quo in TAD, revealing the misleading track of current research and highlighting problematic methods, and evaluation practices. Our position advocates for a shift in focus from solely pursuing novel model designs to improving benchmarking practices, creating non-trivial datasets, and critically evaluating the utility of complex methods against simpler baselines. Our findings demonstrate the need for rigorous evaluation protocols, the creation of simple baselines, and the revelation that state-of-the-art deep anomaly detection models effectively learn linear mappings. These findings suggest the need for more exploration and development of simple and interpretable TAD methods. The increment of model complexity in the state-of-the-art deep-learning based models unfortunately offers very little improvement. We offer insights and suggestions for the field to move forward. Code: https://github.com/ssarfraz/QuoVadisTAD
Position Paper: Quo Vadis, Unsupervised Time Series Anomaly Detection?
May 04, 2024The current state of machine learning scholarship in Timeseries Anomaly Detection (TAD) is plagued by the persistent use of flawed evaluation metrics, inconsistent benchmarking practices, and a lack of proper justification for the choices made in novel deep learning-based model designs. Our paper presents a critical analysis of the status quo in TAD, revealing the misleading track of current research and highlighting problematic methods, and evaluation practices. Our position advocates for a shift in focus from pursuing only the novelty in model design to improving benchmarking practices, creating non-trivial datasets, and placing renewed emphasis on studying the utility of model architectures for specific tasks. Our findings demonstrate the need for rigorous evaluation protocols, the creation of simple baselines, and the revelation that state-of-the-art deep anomaly detection models effectively learn linear mappings. These findings suggest the need for more exploration and development of simple and interpretable TAD methods. The increment of model complexity in the state-of-the-art deep-learning based models unfortunately offers very little improvement. We offer insights and suggestions for the field to move forward.
Hierarchical Nearest Neighbor Graph Embedding for Efficient Dimensionality Reduction
Apr 11, 2022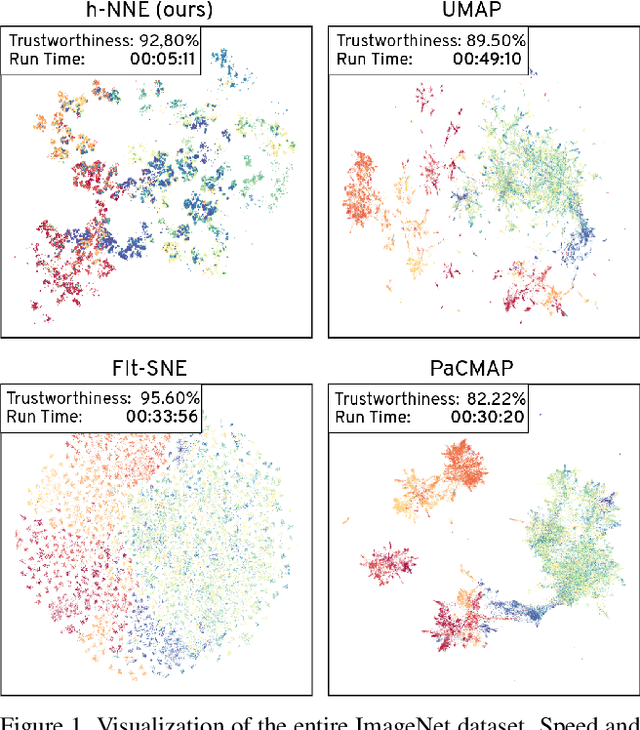

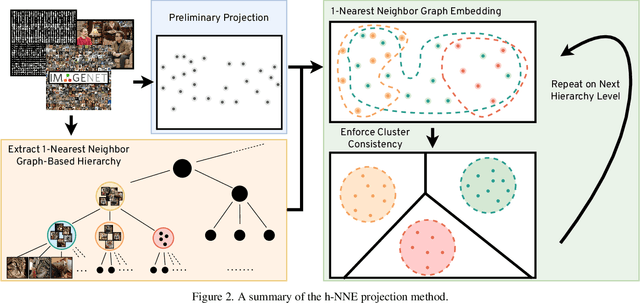
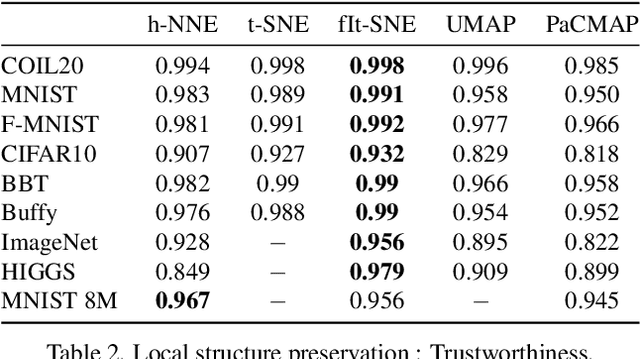
Dimensionality reduction is crucial both for visualization and preprocessing high dimensional data for machine learning. We introduce a novel method based on a hierarchy built on 1-nearest neighbor graphs in the original space which is used to preserve the grouping properties of the data distribution on multiple levels. The core of the proposal is an optimization-free projection that is competitive with the latest versions of t-SNE and UMAP in performance and visualization quality while being an order of magnitude faster in run-time. Furthermore, its interpretable mechanics, the ability to project new data, and the natural separation of data clusters in visualizations make it a general purpose unsupervised dimension reduction technique. In the paper, we argue about the soundness of the proposed method and evaluate it on a diverse collection of datasets with sizes varying from 1K to 11M samples and dimensions from 28 to 16K. We perform comparisons with other state-of-the-art methods on multiple metrics and target dimensions highlighting its efficiency and performance. Code is available at https://github.com/koulakis/h-nne
Is my Driver Observation Model Overconfident? Input-guided Calibration Networks for Reliable and Interpretable Confidence Estimates
Apr 10, 2022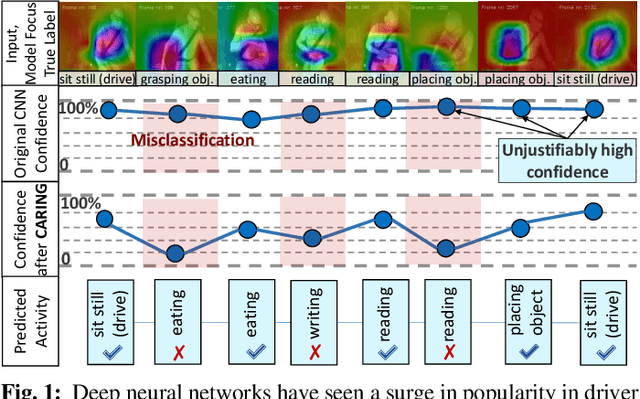
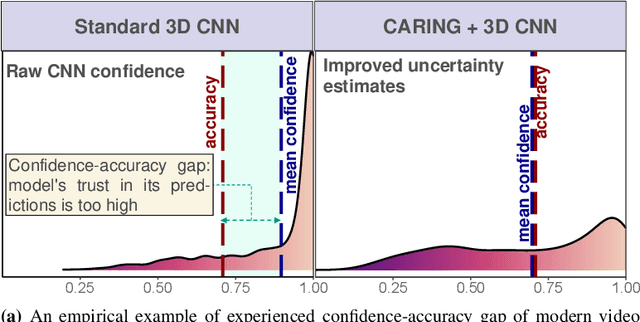
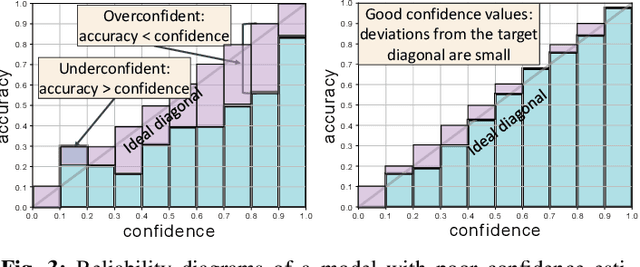

Driver observation models are rarely deployed under perfect conditions. In practice, illumination, camera placement and type differ from the ones present during training and unforeseen behaviours may occur at any time. While observing the human behind the steering wheel leads to more intuitive human-vehicle-interaction and safer driving, it requires recognition algorithms which do not only predict the correct driver state, but also determine their prediction quality through realistic and interpretable confidence measures. Reliable uncertainty estimates are crucial for building trust and are a serious obstacle for deploying activity recognition networks in real driving systems. In this work, we for the first time examine how well the confidence values of modern driver observation models indeed match the probability of the correct outcome and show that raw neural network-based approaches tend to significantly overestimate their prediction quality. To correct this misalignment between the confidence values and the actual uncertainty, we consider two strategies. First, we enhance two activity recognition models often used for driver observation with temperature scaling-an off-the-shelf method for confidence calibration in image classification. Then, we introduce Calibrated Action Recognition with Input Guidance (CARING)-a novel approach leveraging an additional neural network to learn scaling the confidences depending on the video representation. Extensive experiments on the Drive&Act dataset demonstrate that both strategies drastically improve the quality of model confidences, while our CARING model out-performs both, the original architectures and their temperature scaling enhancement, leading to best uncertainty estimates.
Affect-DML: Context-Aware One-Shot Recognition of Human Affect using Deep Metric Learning
Nov 30, 2021


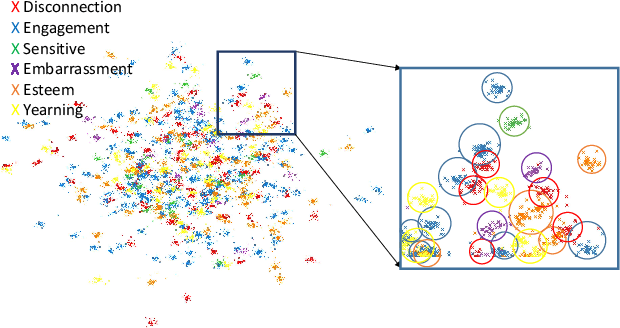
Human affect recognition is a well-established research area with numerous applications, e.g., in psychological care, but existing methods assume that all emotions-of-interest are given a priori as annotated training examples. However, the rising granularity and refinements of the human emotional spectrum through novel psychological theories and the increased consideration of emotions in context brings considerable pressure to data collection and labeling work. In this paper, we conceptualize one-shot recognition of emotions in context -- a new problem aimed at recognizing human affect states in finer particle level from a single support sample. To address this challenging task, we follow the deep metric learning paradigm and introduce a multi-modal emotion embedding approach which minimizes the distance of the same-emotion embeddings by leveraging complementary information of human appearance and the semantic scene context obtained through a semantic segmentation network. All streams of our context-aware model are optimized jointly using weighted triplet loss and weighted cross entropy loss. We conduct thorough experiments on both, categorical and numerical emotion recognition tasks of the Emotic dataset adapted to our one-shot recognition problem, revealing that categorizing human affect from a single example is a hard task. Still, all variants of our model clearly outperform the random baseline, while leveraging the semantic scene context consistently improves the learnt representations, setting state-of-the-art results in one-shot emotion recognition. To foster research of more universal representations of human affect states, we will make our benchmark and models publicly available to the community under https://github.com/KPeng9510/Affect-DML.