 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for Good Tokenizers in Vision Transformer?
Paper and Code
Dec 21, 2022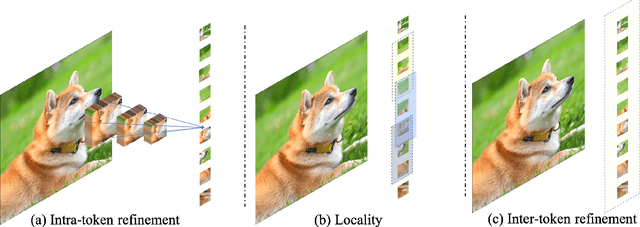



The architecture of transformers, which recently witness booming applications in vision tasks, has pivoted against the widespread convolutional paradigm. Relying on the tokenization process that splits inputs into multiple tokens, transformers are capable of extracting their pairwise relationships using self-attention. While being the stemming building block of transformers, what makes for a good tokenizer has not been well understood in computer vision. In this work, we investigate this uncharted problem from an information trade-off perspective. In addition to unifying and understanding existing structural modifications, our derivation leads to better design strategies for vision tokenizers. The proposed Modulation across Tokens (MoTo) incorporates inter-token modeling capability through normalization. Furthermore, a regularization objective TokenProp is embraced in the standard training regime. Through extensive experiments on various transformer architectures, we observe both improved performance and intriguing properties of these two plug-and-play designs with negligible computational overhead. These observations further indicate the importance of the commonly-omitted designs of tokenizers in vision transformer.