 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecConv: Efficient Recursive Convolutions for Multi-Frequency Representations
Dec 27, 2024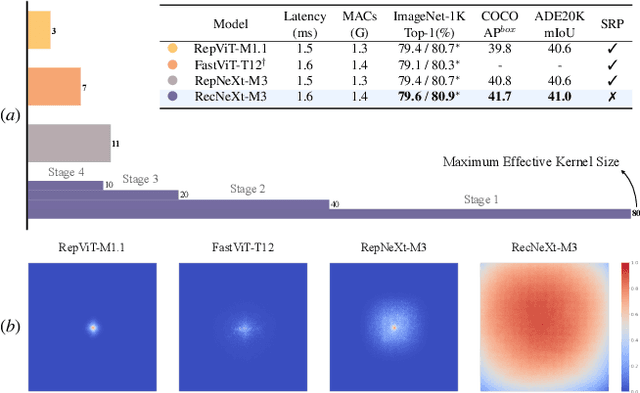
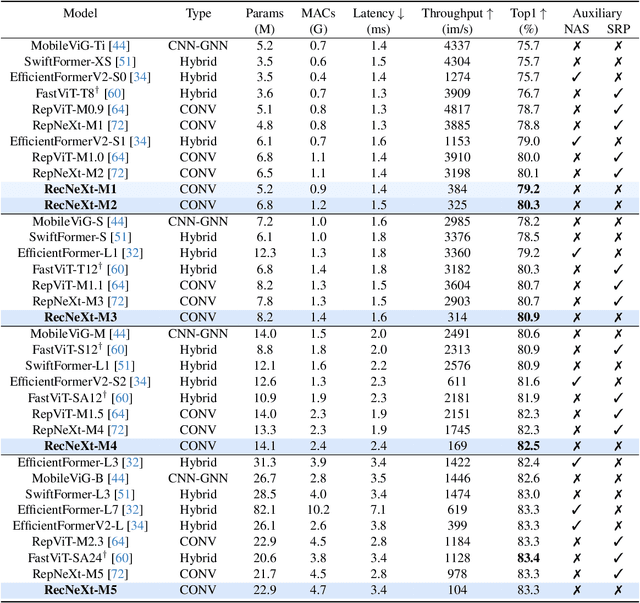
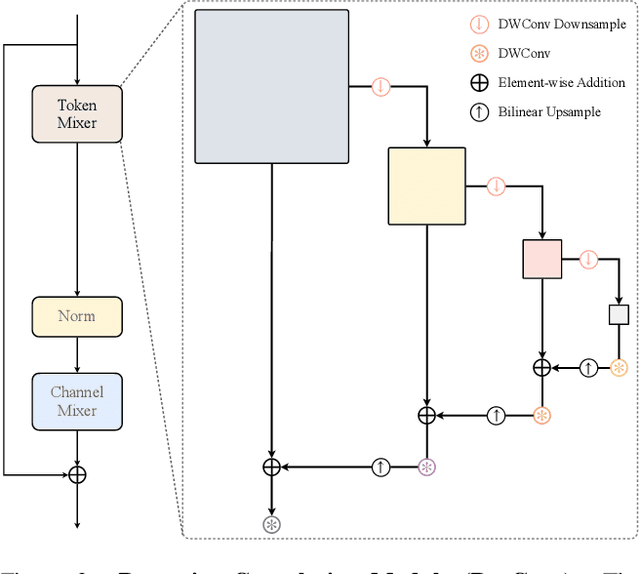
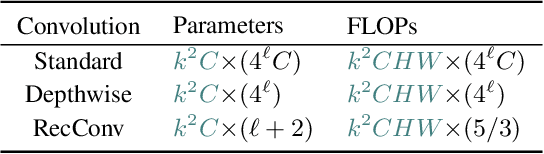
Recent advances in vision transformers (ViTs) have demonstrated the advantage of global modeling capabilities, prompting widespread integration of large-kernel convolutions for enlarging the effective receptive field (ERF). However, the quadratic scaling of parameter count and computational complexity (FLOPs) with respect to kernel size poses significant efficiency and optimization challenges. This paper introduces RecConv, a recursive decomposition strategy that efficiently constructs multi-frequency representations using small-kernel convolutions. RecConv establishes a linear relationship between parameter growth and decomposing levels which determines the effective kernel size $k\times 2^\ell$ for a base kernel $k$ and $\ell$ levels of decomposition, while maintaining constant FLOPs regardless of the ERF expansion. Specifically, RecConv achieves a parameter expansion of only $\ell+2$ times and a maximum FLOPs increase of $5/3$ times, compared to the exponential growth ($4^\ell$) of standard and depthwise convolutions. RecNeXt-M3 outperforms RepViT-M1.1 by 1.9 $AP^{box}$ on COCO with similar FLOPs. This innovation provides a promising avenue towards designing efficient and compact networks across various modalities. Codes and models can be found at \url{https://github.com/suous/RecNeXt}.
RepNeXt: A Fast Multi-Scale CNN using Structural Reparameterization
Jun 23, 2024In the realm of resource-constrained mobile vision tasks, the pursuit of efficiency and performance consistently drives innovation in lightweight Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). While ViTs excel at capturing global context through self-attention mechanisms, their deployment in resource-limited environments is hindered by computational complexity and latency. Conversely, lightweight CNNs are favored for their parameter efficiency and low latency. This study investigates the complementary advantages of CNNs and ViTs to develop a versatile vision backbone tailored for resource-constrained applications. We introduce RepNeXt, a novel model series integrates multi-scale feature representations and incorporates both serial and parallel structural reparameterization (SRP) to enhance network depth and width without compromising inference speed. Extensive experiments demonstrate RepNeXt's superiority over current leading lightweight CNNs and ViTs, providing advantageous latency across various vision benchmarks. RepNeXt-M4 matches RepViT-M1.5's 82.3\% accuracy on ImageNet within 1.5ms on an iPhone 12, outperforms its AP$^{box}$ by 1.1 on MS-COCO, and reduces parameters by 0.7M. Codes and models are available at https://github.com/suous/RepNeXt.