 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContourFormer:Real-Time Contour-Based End-to-End Instance Segmentation Transformer
Jan 30, 2025



This paper presents Contourformer, a real-time contour-based instance segmentation algorithm. The method is fully based on the DETR paradigm and achieves end-to-end inference through iterative and progressive mechanisms to optimize contours. To improve efficiency and accuracy, we develop two novel techniques: sub-contour decoupling mechanisms and contour fine-grained distribution refinement. In the sub-contour decoupling mechanism, we propose a deformable attention-based module that adaptively selects sampling regions based on the current predicted contour, enabling more effective capturing of object boundary information. Additionally, we design a multi-stage optimization process to enhance segmentation precision by progressively refining sub-contours. The contour fine-grained distribution refinement technique aims to further improve the ability to express fine details of contours. These innovations enable Contourformer to achieve stable and precise segmentation for each instance while maintaining real-time performance. Extensive experiments demonstrate the superior performance of Contourformer on multiple benchmark datasets, including SBD, COCO, and KINS. We conduct comprehensive evaluations and comparisons with existing state-of-the-art methods, showing significant improvements in both accuracy and inference speed. This work provides a new solution for contour-based instance segmentation tasks and lays a foundation for future research, with the potential to become a strong baseline method in this field.
Ellipse Regression with Predicted Uncertainties for Accurate Multi-View 3D Object Estimation
Dec 27, 2020
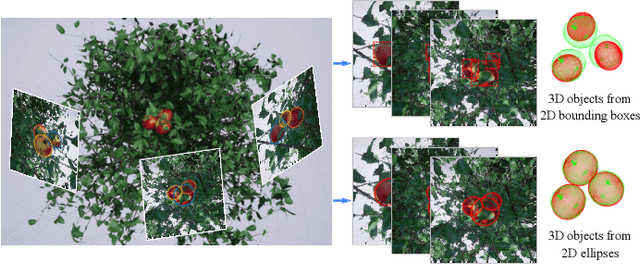

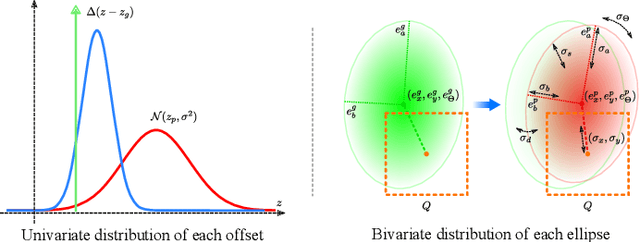
Convolutional neural network (CNN) based architectures, such as Mask R-CNN, constitute the state of the art in object detection and segmentation. Recently, these methods have been extended for model-based segmentation where the network outputs the parameters of a geometric model (e.g. an ellipse) directly. This work considers objects whose three-dimensional models can be represented as ellipsoids. We present a variant of Mask R-CNN for estimating the parameters of ellipsoidal objects by segmenting each object and accurately regressing the parameters of projection ellipses. We show that model regression is sensitive to the underlying occlusion scenario and that prediction quality for each object needs to be characterized individually for accurate 3D object estimation. We present a novel ellipse regression loss which can learn the offset parameters with their uncertainties and quantify the overall geometric quality of detection for each ellipse. These values, in turn, allow us to fuse multi-view detections to obtain 3D ellipsoid parameters in a principled fashion. The experiments on both synthetic and real datasets quantitatively demonstrate the high accuracy of our proposed method in estimating 3D objects under heavy occlusions compared to previous state-of-the-art methods.
Ellipse R-CNN: Learning to Infer Elliptical Object from Clustering and Occlusion
Jan 30, 2020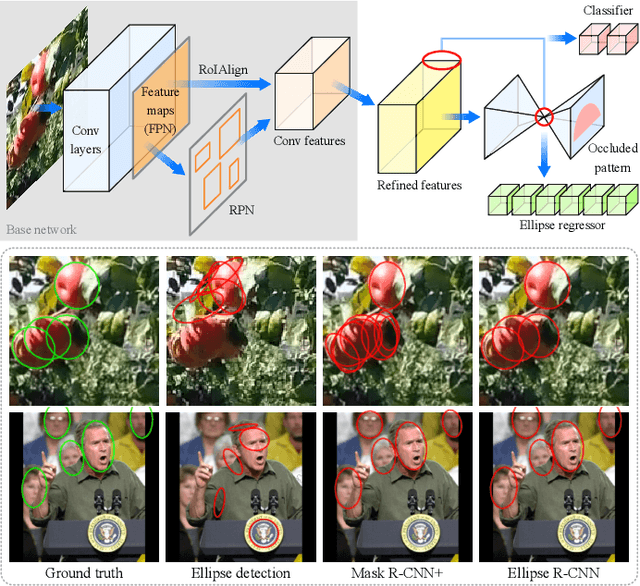



Images of heavily occluded objects in cluttered scenes, such as fruit clusters in trees, are hard to segment. To further retrieve the 3D size and 6D pose of each individual object in such cases, bounding boxes are not reliable from multiple views since only a little portion of the object's geometry is captured. We introduce the first CNN-based ellipse detector, called Ellipse R-CNN, to represent and infer occluded objects as ellipses. We first propose a robust and compact ellipse regression based on the Mask R-CNN architecture for elliptical object detection. Our method can infer the parameters of multiple elliptical objects even they are occluded by other neighboring objects. For better occlusion handling, we exploit refined feature regions for the regression stage, and integrate the U-Net structure for learning different occlusion patterns to compute the final detection score. The correctness of ellipse regression is validated through experiments performed on synthetic data of clustered ellipses. We further quantitatively and qualitatively demonstrate that our approach outperforms the state-of-the-art model (i.e., Mask R-CNN followed by ellipse fitting) and its three variants on both synthetic and real datasets of occluded and clustered elliptical objects.
Semantic Mapping for Orchard Environments by Merging Two-Sides Reconstructions of Tree Rows
Jan 11, 2019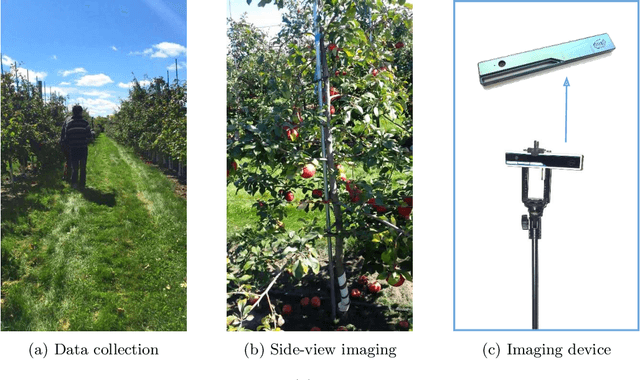

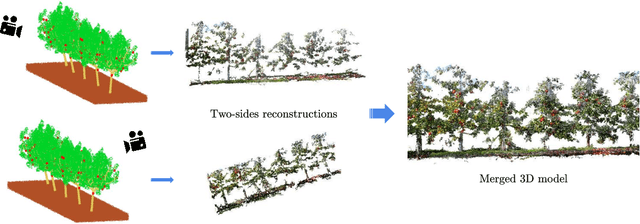

Measuring semantic traits for phenotyping is an essential but labor-intensive activity in horticulture. Researchers often rely on manual measurements which may not be accurate for tasks such as measuring tree volume. To improve the accuracy of such measurements and to automate the process, we consider the problem of building coherent three dimensional (3D) reconstructions of orchard rows. Even though 3D reconstructions of side views can be obtained using standard mapping techniques, merging the two side-views is difficult due to the lack of overlap between the two partial reconstructions. Our first main contribution in this paper is a novel method that utilizes global features and semantic information to obtain an initial solution aligning the two sides. Our mapping approach then refines the 3D model of the entire tree row by integrating semantic information common to both sides, and extracted using our novel robust detection and fitting algorithms. Next, we present a vision system to measure semantic traits from the optimized 3D model that is built from the RGB or RGB-D data captured by only a camera. Specifically, we show how canopy volume, trunk diameter, tree height and fruit count can be automatically obtained in real orchard environments. The experiment results from multiple datasets quantitatively demonstrate the high accuracy and robustness of our method.
A Novel Method for the Extrinsic Calibration of a 2D Laser Rangefinder and a Camera
Aug 31, 2018
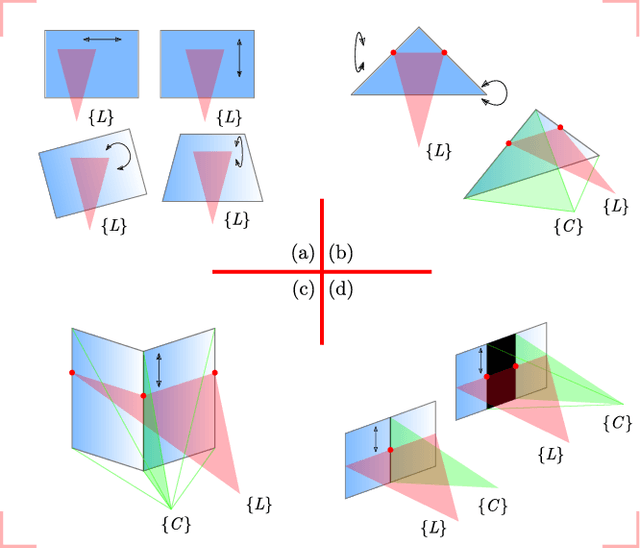
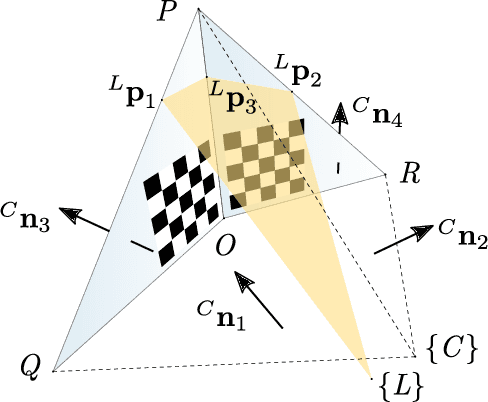
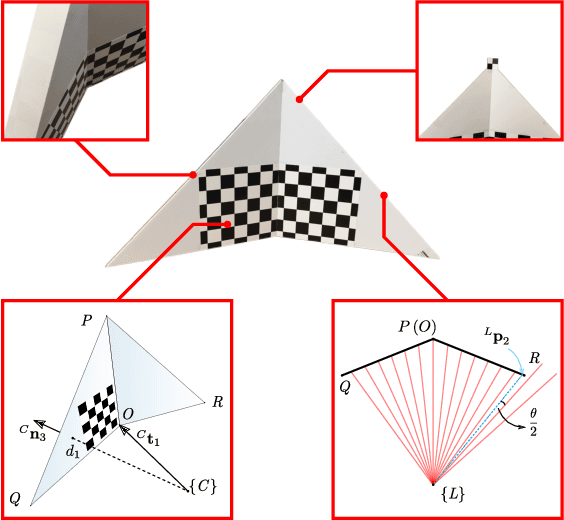
We present a novel method for extrinsically calibrating a camera and a 2D Laser Rangefinder (LRF) whose beams are invisible from the camera image. We show that point-to-plane constraints from a single observation of a V-shaped calibration pattern composed of two non-coplanar triangles suffice to uniquely constrain the relative pose between two sensors. Next, we present an approach to obtain analytical solutions using point-to-plane constraints from single or multiple observations. Along the way, we also show that previous solutions, in contrast to our method, have inherent ambiguities and therefore must rely on a good initial estimate. Real and synthetic experiments validate our method and show that it achieves better accuracy than previous methods.
* 12 pages, 12 figures
Tree Morphology for Phenotyping from Semantics-Based Mapping in Orchard Environments
Apr 16, 2018
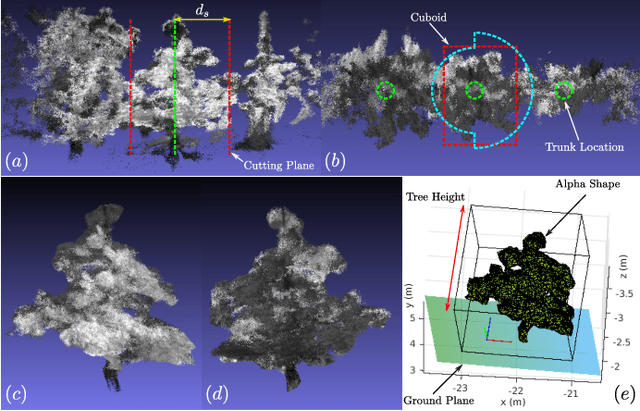

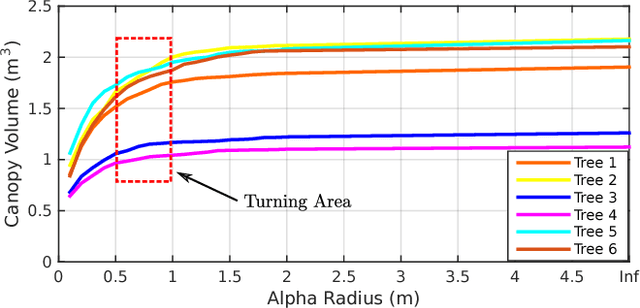
Measuring tree morphology for phenotyping is an essential but labor-intensive activity in horticulture. Researchers often rely on manual measurements which may not be accurate for example when measuring tree volume. Recent approaches on automating the measurement process rely on LIDAR measurements coupled with high-accuracy GPS. Usually each side of a row is reconstructed independently and then merged using GPS information. Such approaches have two disadvantages: (1) they rely on specialized and expensive equipment, and (2) since the reconstruction process does not simultaneously use information from both sides, side reconstructions may not be accurate. We also show that standard loop closure methods do not necessarily align tree trunks well. In this paper, we present a novel vision system that employs only an RGB-D camera to estimate morphological parameters. A semantics-based mapping algorithm merges the two-sides 3D models of tree rows, where integrated semantic information is obtained and refined by robust fitting algorithms. We focus on measuring tree height, canopy volume and trunk diameter from the optimized 3D model. Experiments conducted in real orchards quantitatively demonstrate the accuracy of our method.