 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Speaker-Attributed ASR with Token-Level Speaker Embeddings
Paper and Code
Mar 30, 2022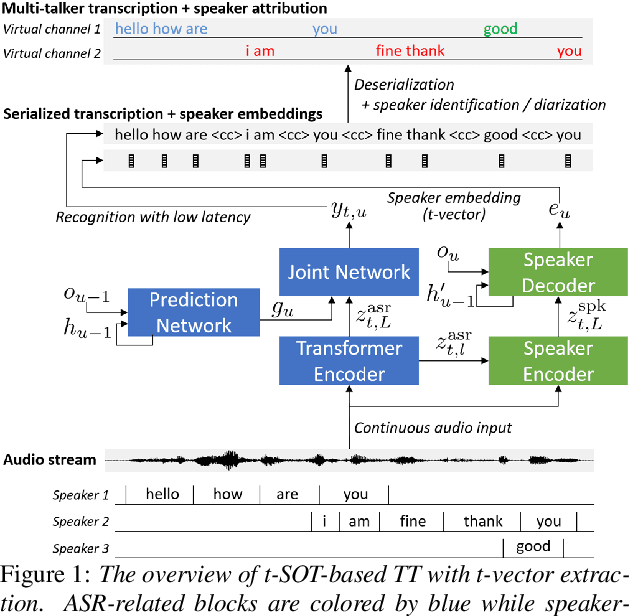
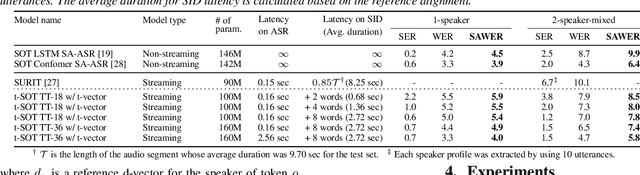
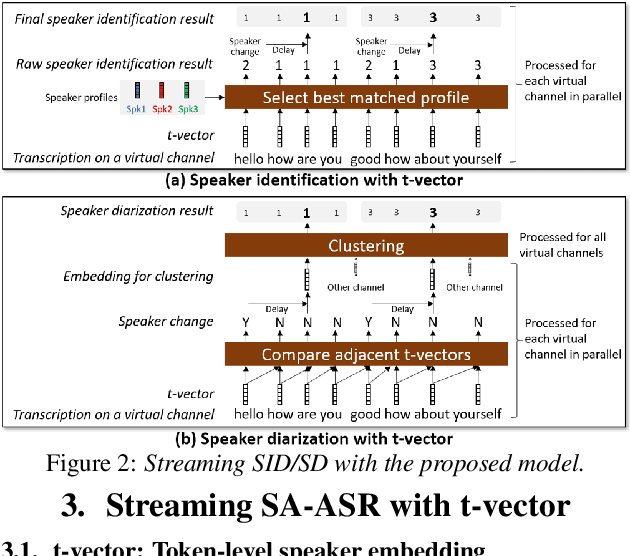

This paper presents a streaming speaker-attributed automatic speech recognition (SA-ASR) model that can recognize "who spoke what" with low latency even when multiple people are speaking simultaneously. Our model is based on token-level serialized output training (t-SOT) which was recently proposed to transcribe multi-talker speech in a streaming fashion. To further recognize speaker identities, we propose an encoder-decoder based speaker embedding extractor that can estimate a speaker representation for each recognized token not only from non-overlapping speech but also from overlapping speech. The proposed speaker embedding, named t-vector, is extracted synchronously with the t-SOT ASR model, enabling joint execution of speaker identification (SID) or speaker diarization (SD) with the multi-talker transcription with low latency. We evaluate the proposed model for a joint task of ASR and SID/SD by using LibriSpeechMix and LibriCSS corpora. The proposed model achieves substantially better accuracy than a prior streaming model and shows comparable or sometimes even superior results to the state-of-the-art offline SA-ASR model.