 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Self-supervised Learning of Speech Representation from a Mutual Information Perspective
Paper and Code
Jan 16, 2024
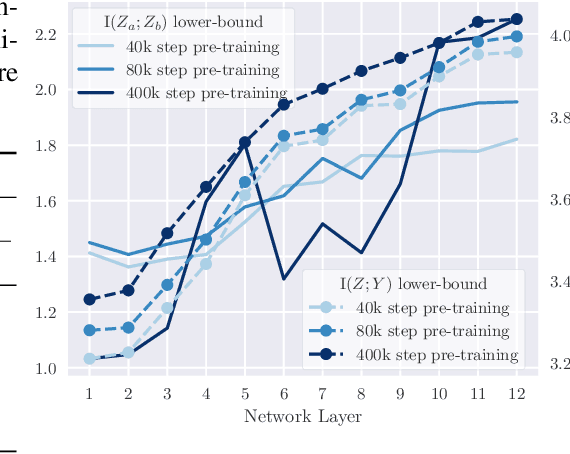
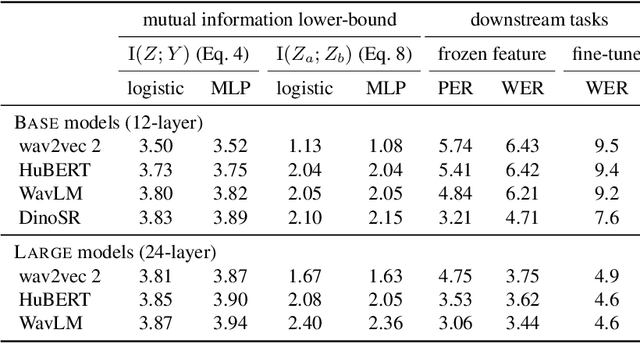

Existing studies on self-supervised speech representation learning have focused on developing new training methods and applying pre-trained models for different applications. However, the quality of these models is often measured by the performance of different downstream tasks. How well the representations access the information of interest is less studied. In this work, we take a closer look into existing self-supervised methods of speech from an information-theoretic perspective. We aim to develop metrics using mutual information to help practical problems such as model design and selection. We use linear probes to estimate the mutual information between the target information and learned representations, showing another insight into the accessibility to the target information from speech representations. Further, we explore the potential of evaluating representations in a self-supervised fashion, where we estimate the mutual information between different parts of the data without using any labels. Finally, we show that both supervised and unsupervised measures echo the performance of the models on layer-wise linear probing and speech recognition.