 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEC: Summary Preference Decomposition for Low-Resource Abstractive Summarization
Paper and Code
Mar 24, 2023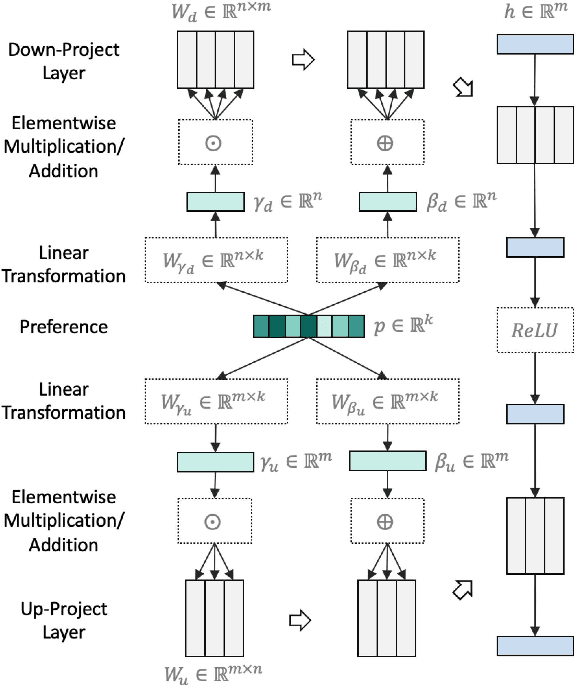



Neural abstractive summarization has been widely studied and achieved great success with large-scale corpora. However, the considerable cost of annotating data motivates the need for learning strategies under low-resource settings. In this paper, we investigate the problems of learning summarizers with only few examples and propose corresponding methods for improvements. First, typical transfer learning methods are prone to be affected by data properties and learning objectives in the pretext tasks. Therefore, based on pretrained language models, we further present a meta learning framework to transfer few-shot learning processes from source corpora to the target corpus. Second, previous methods learn from training examples without decomposing the content and preference. The generated summaries could therefore be constrained by the preference bias in the training set, especially under low-resource settings. As such, we propose decomposing the contents and preferences during learning through the parameter modulation, which enables control over preferences during inference. Third, given a target application, specifying required preferences could be non-trivial because the preferences may be difficult to derive through observations. Therefore, we propose a novel decoding method to automatically estimate suitable preferences and generate corresponding summary candidates from the few training examples. Extensive experiments demonstrate that our methods achieve state-of-the-art performance on six diverse corpora with 30.11%/33.95%/27.51% and 26.74%/31.14%/24.48% average improvements on ROUGE-1/2/L under 10- and 100-example settings.