 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Manipulation Policy Modeling with Visuomotor Latent Diffusion
Paper and Code
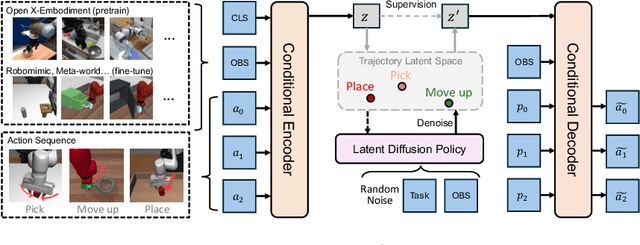
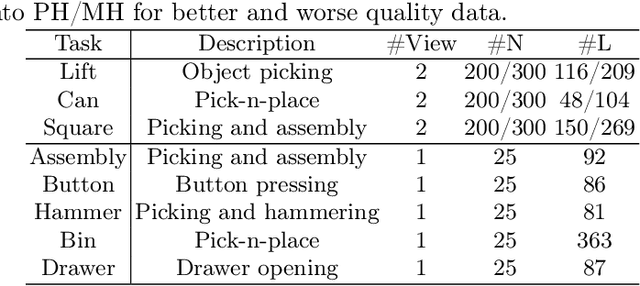
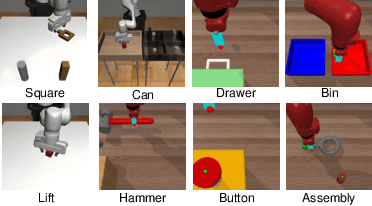
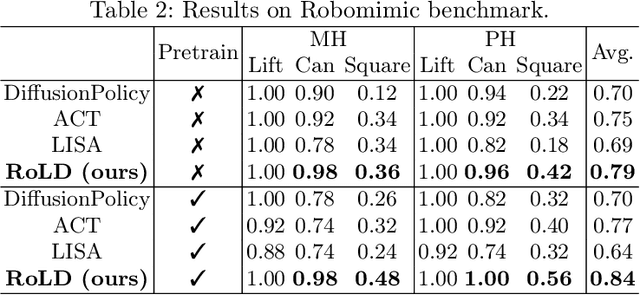
Modeling a generalized visuomotor policy has been a longstanding challenge for both computer vision and robotics communities. Existing approaches often fail to efficiently leverage cross-dataset resources or rely on heavy Vision-Language models, which require substantial computational resources, thereby limiting their multi-task performance and application potential. In this paper, we introduce a novel paradigm that effectively utilizes latent modeling of manipulation skills and an efficient visuomotor latent diffusion policy, which enhances the utilizing of existing cross-embodiment and cross-environment datasets, thereby improving multi-task capabilities. Our methodology consists of two decoupled phases: action modeling and policy modeling. Firstly, we introduce a task-agnostic, embodiment-aware trajectory latent autoencoder for unified action skills modeling. This step condenses action data and observation into a condensed latent space, effectively benefiting from large-scale cross-datasets. Secondly, we propose to use a visuomotor latent diffusion policy that recovers target skill latent from noises for effective task execution. We conducted extensive experiments on two widely used benchmarks, and the results demonstrate the effectiveness of our proposed paradigms on multi-tasking and pre-training. Code is available at https://github.com/AlbertTan404/RoLD.