 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyViT: Fast Pretraining Distillation for Small Vision Transformers
Paper and Code
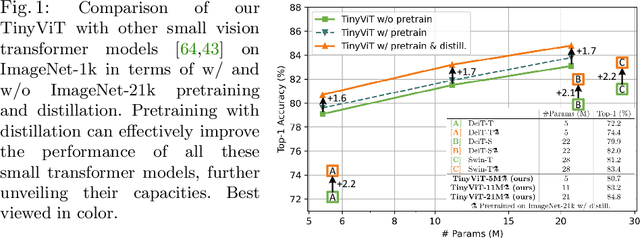
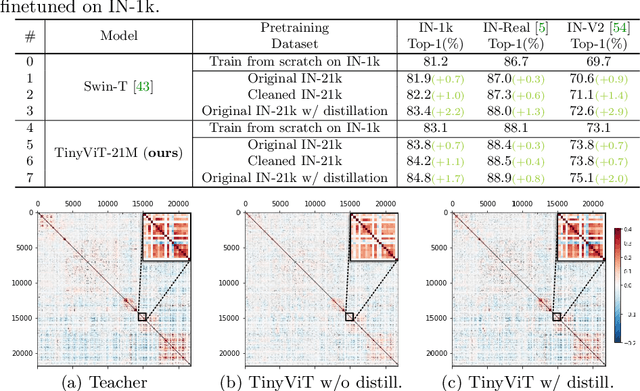
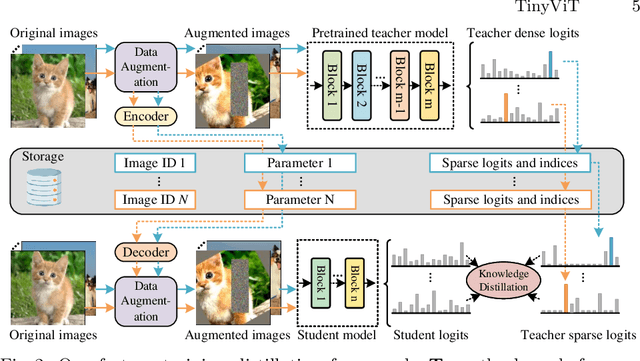

Vision transformer (ViT) recently has drawn great attention in computer vision due to its remarkable model capability. However, most prevailing ViT models suffer from huge number of parameters, restricting their applicability on devices with limited resources. To alleviate this issue, we propose TinyViT, a new family of tiny and efficient small vision transformers pretrained on large-scale datasets with our proposed fast distillation framework. The central idea is to transfer knowledge from large pretrained models to small ones, while enabling small models to get the dividends of massive pretraining data. More specifically, we apply distillation during pretraining for knowledge transfer. The logits of large teacher models are sparsified and stored in disk in advance to save the memory cost and computation overheads. The tiny student transformers are automatically scaled down from a large pretrained model with computation and parameter constraints. Comprehensive experiments demonstrate the efficacy of TinyViT. It achieves a top-1 accuracy of 84.8% on ImageNet-1k with only 21M parameters, being comparable to Swin-B pretrained on ImageNet-21k while using 4.2 times fewer parameters. Moreover, increasing image resolutions, TinyViT can reach 86.5% accuracy, being slightly better than Swin-L while using only 11% parameters. Last but not the least, we demonstrate a good transfer ability of TinyViT on various downstream tasks. Code and models are available at https://github.com/microsoft/Cream/tree/main/TinyViT.