 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multiple Representations with Inconsistency-Guided Detail Regularization for Mask-Guided Matting
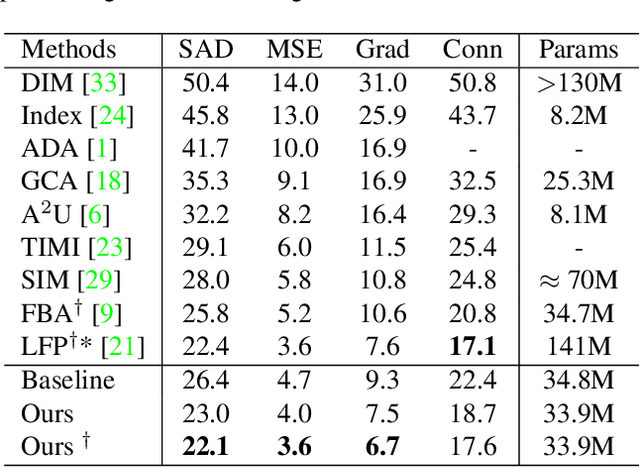
Mar 28, 2024Mask-guided matting networks have achieved significant improvements and have shown great potential in practical applications in recent years. However, simply learning matting representation from synthetic and lack-of-real-world-diversity matting data, these approaches tend to overfit low-level details in wrong regions, lack generalization to objects with complex structures and real-world scenes such as shadows, as well as suffer from interference of background lines or textures. To address these challenges, in this paper, we propose a novel auxiliary learning framework for mask-guided matting models, incorporating three auxiliary tasks: semantic segmentation, edge detection, and background line detection besides matting, to learn different and effective representations from different types of data and annotations. Our framework and model introduce the following key aspects: (1) to learn real-world adaptive semantic representation for objects with diverse and complex structures under real-world scenes, we introduce extra semantic segmentation and edge detection tasks on more diverse real-world data with segmentation annotations; (2) to avoid overfitting on low-level details, we propose a module to utilize the inconsistency between learned segmentation and matting representations to regularize detail refinement; (3) we propose a novel background line detection task into our auxiliary learning framework, to suppress interference of background lines or textures. In addition, we propose a high-quality matting benchmark, Plant-Mat, to evaluate matting methods on complex structures. Extensively quantitative and qualitative results show that our approach outperforms state-of-the-art mask-guided methods.
PA-SAM: Prompt Adapter SAM for High-Quality Image Segmentation
Jan 23, 2024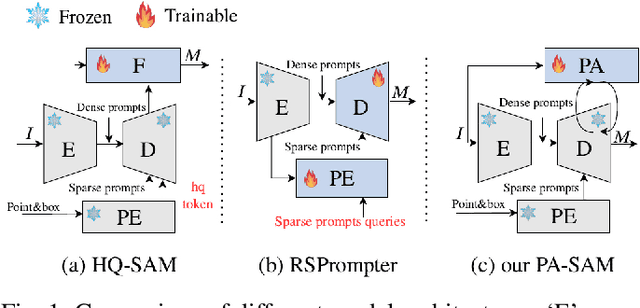
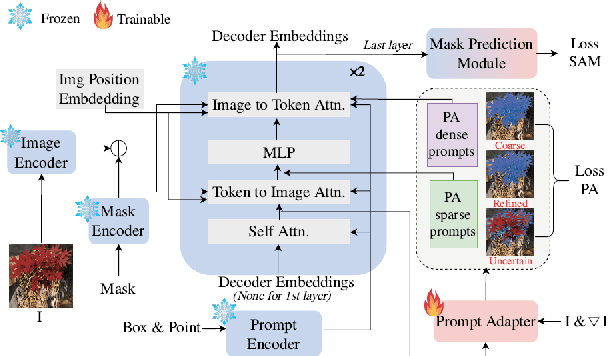
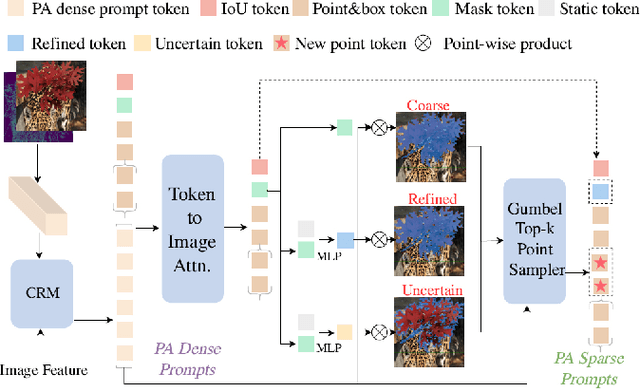

The Segment Anything Model (SAM) has exhibited outstanding performance in various image segmentation tasks. Despite being trained with over a billion masks, SAM faces challenges in mask prediction quality in numerous scenarios, especially in real-world contexts. In this paper, we introduce a novel prompt-driven adapter into SAM, namely Prompt Adapter Segment Anything Model (PA-SAM), aiming to enhance the segmentation mask quality of the original SAM. By exclusively training the prompt adapter, PA-SAM extracts detailed information from images and optimizes the mask decoder feature at both sparse and dense prompt levels, improving the segmentation performance of SAM to produce high-quality masks. Experimental results demonstrate that our PA-SAM outperforms other SAM-based methods in high-quality, zero-shot, and open-set segmentation. We're making the source code and models available at https://github.com/xzz2/pa-sam.
Trimap-guided Feature Mining and Fusion Network for Natural Image Matting
Dec 03, 2021
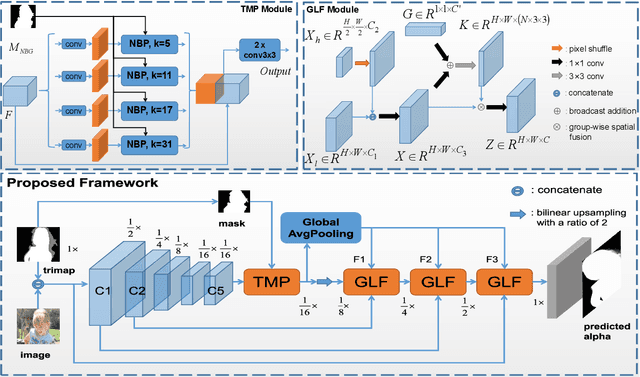
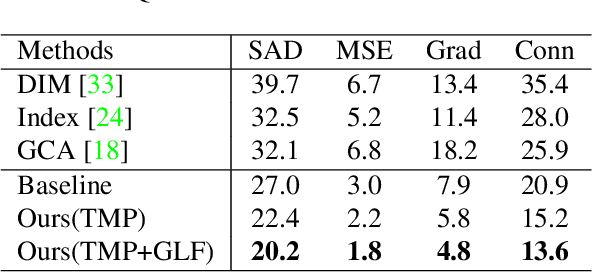
Utilizing trimap guidance and fusing multi-level features are two important issues for trimap-based matting with pixel-level prediction. To utilize trimap guidance, most existing approaches simply concatenate trimaps and images together to feed a deep network or apply an extra network to extract more trimap guidance, which meets the conflict between efficiency and effectiveness. For emerging content-based feature fusion, most existing matting methods only focus on local features which lack the guidance of a global feature with strong semantic information related to the interesting object. In this paper, we propose a trimap-guided feature mining and fusion network consisting of our trimap-guided non-background multi-scale pooling (TMP) module and global-local context-aware fusion (GLF) modules. Considering that trimap provides strong semantic guidance, our TMP module focuses effective feature mining on interesting objects under the guidance of trimap without extra parameters. Furthermore, our GLF modules use global semantic information of interesting objects mined by our TMP module to guide an effective global-local context-aware multi-level feature fusion. In addition, we build a common interesting object matting (CIOM) dataset to advance high-quality image matting. Experimental results on the Composition-1k test set, Alphamatting benchmark, and our CIOM test set demonstrate that our method outperforms state-of-the-art approaches. Code and models will be publicly available soon.
LRNNet: A Light-Weighted Network with Efficient Reduced Non-Local Operation for Real-Time Semantic Segmentation
Jun 04, 2020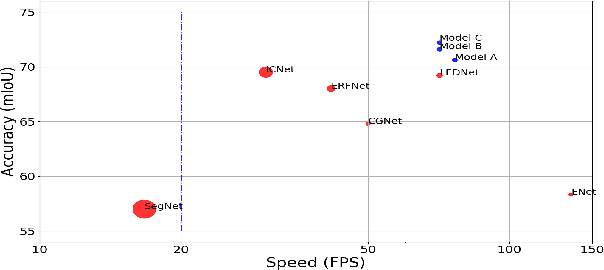
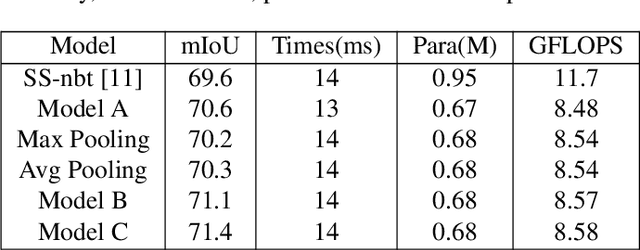
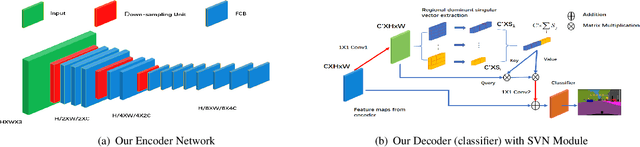
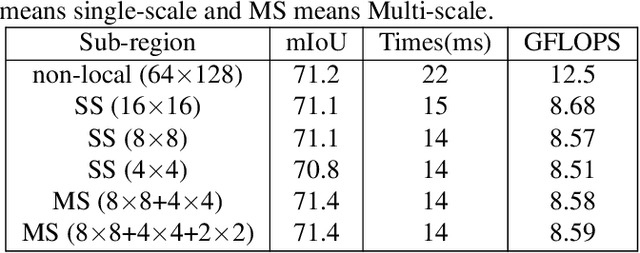
The recent development of light-weighted neural networks has promoted the applications of deep learning under resource constraints and mobile applications. Many of these applications need to perform a real-time and efficient prediction for semantic segmentation with a light-weighted network. This paper introduces a light-weighted network with an efficient reduced non-local module (LRNNet) for efficient and realtime semantic segmentation. We proposed a factorized convolutional block in ResNet-Style encoder to achieve more lightweighted, efficient and powerful feature extraction. Meanwhile, our proposed reduced non-local module utilizes spatial regional dominant singular vectors to achieve reduced and more representative non-local feature integration with much lower computation and memory cost. Experiments demonstrate our superior trade-off among light-weight, speed, computation and accuracy. Without additional processing and pretraining, LRNNet achieves 72.2% mIoU on Cityscapes test dataset only using the fine annotation data for training with only 0.68M parameters and with 71 FPS on a GTX 1080Ti card.