 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Visual Representation Learning by Synchronous Momentum Grouping
Jul 13, 2022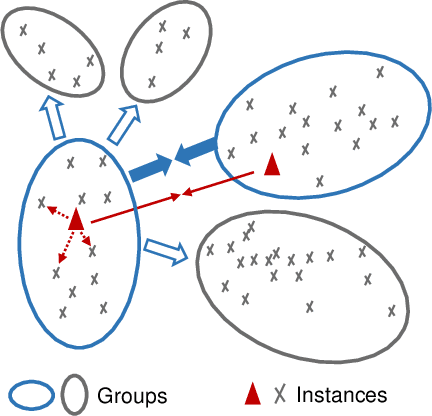
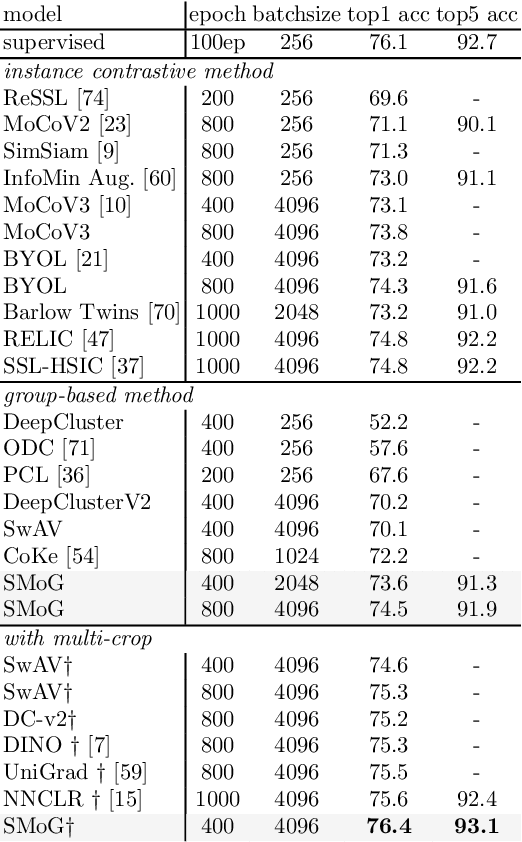
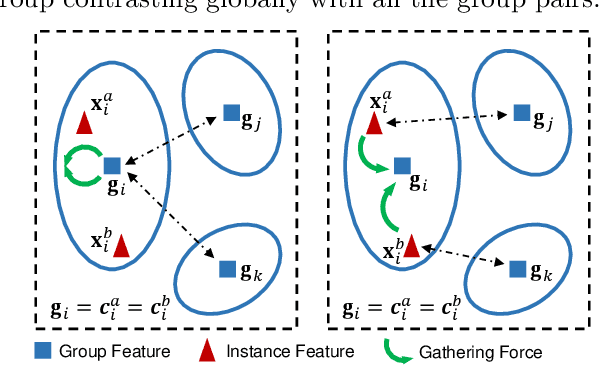
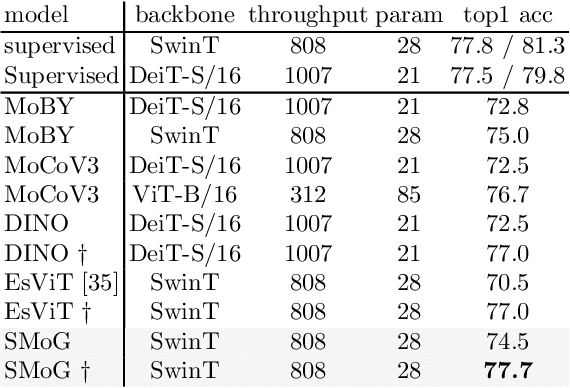
In this paper, we propose a genuine group-level contrastive visual representation learning method whose linear evaluation performance on ImageNet surpasses the vanilla supervised learning. Two mainstream unsupervised learning schemes are the instance-level contrastive framework and clustering-based schemes. The former adopts the extremely fine-grained instance-level discrimination whose supervisory signal is not efficient due to the false negatives. Though the latter solves this, they commonly come with some restrictions affecting the performance. To integrate their advantages, we design the SMoG method. SMoG follows the framework of contrastive learning but replaces the contrastive unit from instance to group, mimicking clustering-based methods. To achieve this, we propose the momentum grouping scheme which synchronously conducts feature grouping with representation learning. In this way, SMoG solves the problem of supervisory signal hysteresis which the clustering-based method usually faces, and reduces the false negatives of instance contrastive methods. We conduct exhaustive experiments to show that SMoG works well on both CNN and Transformer backbones. Results prove that SMoG has surpassed the current SOTA unsupervised representation learning methods. Moreover, its linear evaluation results surpass the performances obtained by vanilla supervised learning and the representation can be well transferred to downstream tasks.
Trimap-guided Feature Mining and Fusion Network for Natural Image Matting
Dec 03, 2021
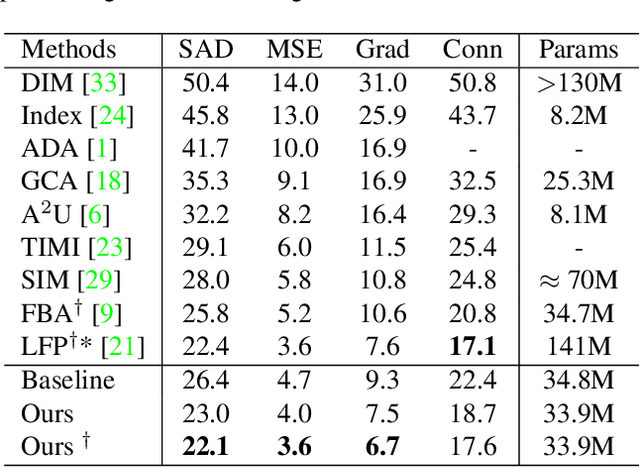
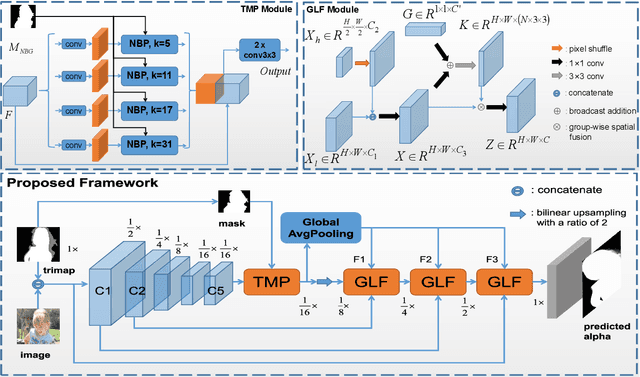
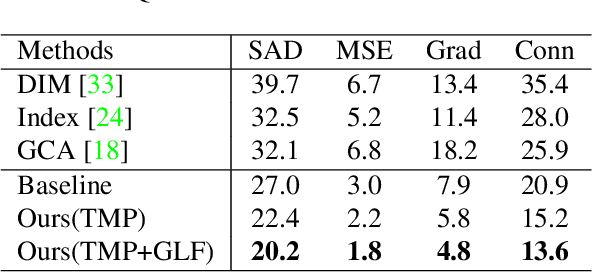
Utilizing trimap guidance and fusing multi-level features are two important issues for trimap-based matting with pixel-level prediction. To utilize trimap guidance, most existing approaches simply concatenate trimaps and images together to feed a deep network or apply an extra network to extract more trimap guidance, which meets the conflict between efficiency and effectiveness. For emerging content-based feature fusion, most existing matting methods only focus on local features which lack the guidance of a global feature with strong semantic information related to the interesting object. In this paper, we propose a trimap-guided feature mining and fusion network consisting of our trimap-guided non-background multi-scale pooling (TMP) module and global-local context-aware fusion (GLF) modules. Considering that trimap provides strong semantic guidance, our TMP module focuses effective feature mining on interesting objects under the guidance of trimap without extra parameters. Furthermore, our GLF modules use global semantic information of interesting objects mined by our TMP module to guide an effective global-local context-aware multi-level feature fusion. In addition, we build a common interesting object matting (CIOM) dataset to advance high-quality image matting. Experimental results on the Composition-1k test set, Alphamatting benchmark, and our CIOM test set demonstrate that our method outperforms state-of-the-art approaches. Code and models will be publicly available soon.
LRNNet: A Light-Weighted Network with Efficient Reduced Non-Local Operation for Real-Time Semantic Segmentation
Jun 04, 2020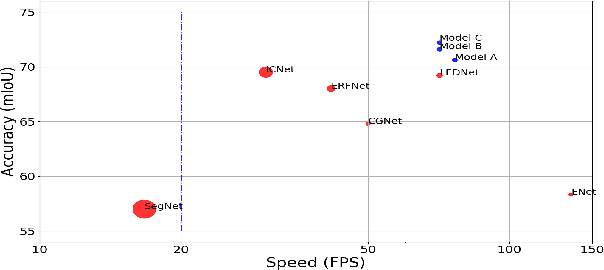
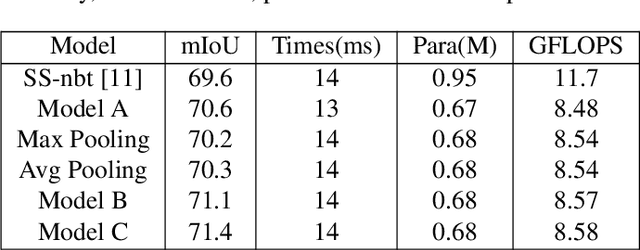
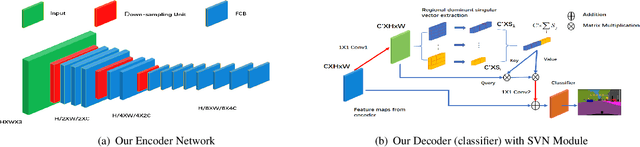
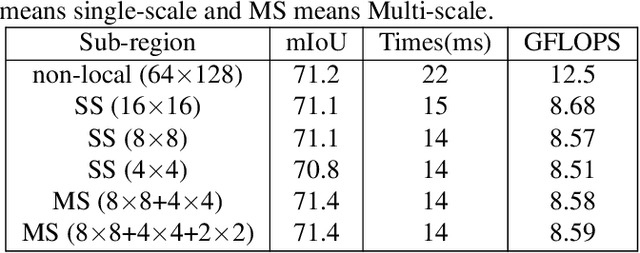
The recent development of light-weighted neural networks has promoted the applications of deep learning under resource constraints and mobile applications. Many of these applications need to perform a real-time and efficient prediction for semantic segmentation with a light-weighted network. This paper introduces a light-weighted network with an efficient reduced non-local module (LRNNet) for efficient and realtime semantic segmentation. We proposed a factorized convolutional block in ResNet-Style encoder to achieve more lightweighted, efficient and powerful feature extraction. Meanwhile, our proposed reduced non-local module utilizes spatial regional dominant singular vectors to achieve reduced and more representative non-local feature integration with much lower computation and memory cost. Experiments demonstrate our superior trade-off among light-weight, speed, computation and accuracy. Without additional processing and pretraining, LRNNet achieves 72.2% mIoU on Cityscapes test dataset only using the fine annotation data for training with only 0.68M parameters and with 71 FPS on a GTX 1080Ti card.
Hierarchical Opacity Propagation for Image Matting
Apr 07, 2020
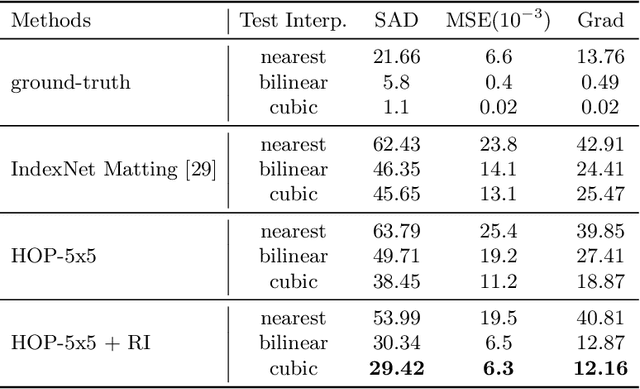
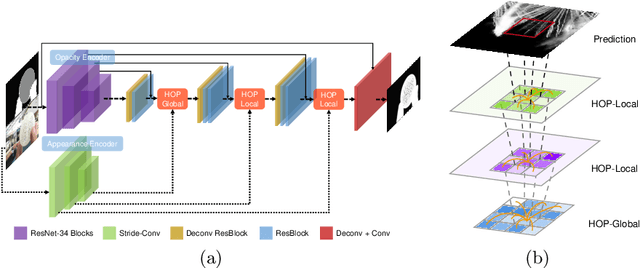
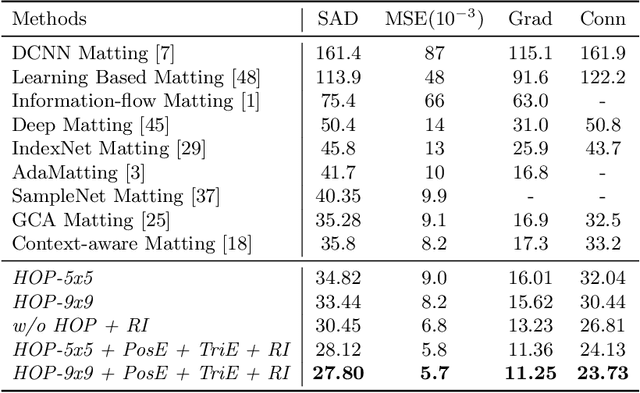
Natural image matting is a fundamental problem in computational photography and computer vision. Deep neural networks have seen the surge of successful methods in natural image matting in recent years. In contrast to traditional propagation-based matting methods, some top-tier deep image matting approaches tend to perform propagation in the neural network implicitly. A novel structure for more direct alpha matte propagation between pixels is in demand. To this end, this paper presents a hierarchical opacity propagation (HOP) matting method, where the opacity information is propagated in the neighborhood of each point at different semantic levels. The hierarchical structure is based on one global and multiple local propagation blocks. With the HOP structure, every feature point pair in high-resolution feature maps will be connected based on the appearance of input image. We further propose a scale-insensitive positional encoding tailored for image matting to deal with the unfixed size of input image and introduce the random interpolation augmentation into image matting. Extensive experiments and ablation study show that HOP matting is capable of outperforming state-of-the-art matting methods.
Natural Image Matting via Guided Contextual Attention
Jan 13, 2020

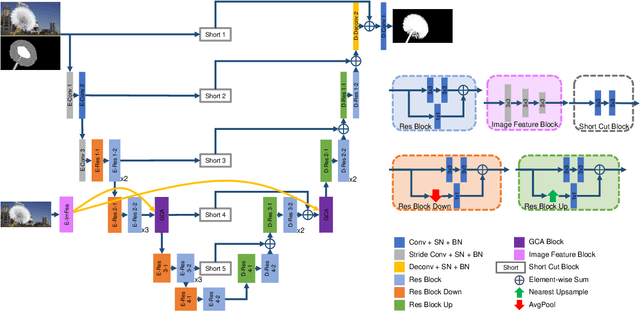
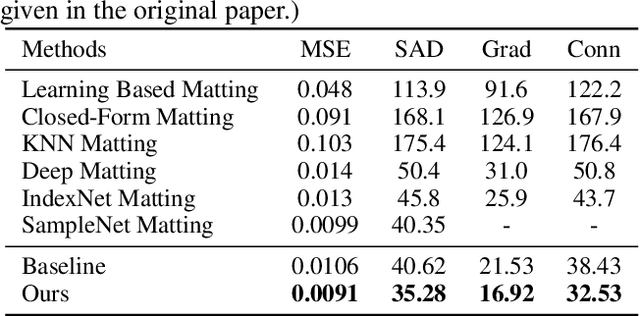
Over the last few years, deep learning based approaches have achieved outstanding improvements in natural image matting. Many of these methods can generate visually plausible alpha estimations, but typically yield blurry structures or textures in the semitransparent area. This is due to the local ambiguity of transparent objects. One possible solution is to leverage the far-surrounding information to estimate the local opacity. Traditional affinity-based methods often suffer from the high computational complexity, which are not suitable for high resolution alpha estimation. Inspired by affinity-based method and the successes of contextual attention in inpainting, we develop a novel end-to-end approach for natural image matting with a guided contextual attention module, which is specifically designed for image matting. Guided contextual attention module directly propagates high-level opacity information globally based on the learned low-level affinity. The proposed method can mimic information flow of affinity-based methods and utilize rich features learned by deep neural networks simultaneously. Experiment results on Composition-1k testing set and alphamatting.com benchmark dataset demonstrate that our method outperforms state-of-the-art approaches in natural image matting. Code and models are available at https://github.com/Yaoyi-Li/GCA-Matting.
Inductive Guided Filter: Real-time Deep Image Matting with Weakly Annotated Masks on Mobile Devices
May 16, 2019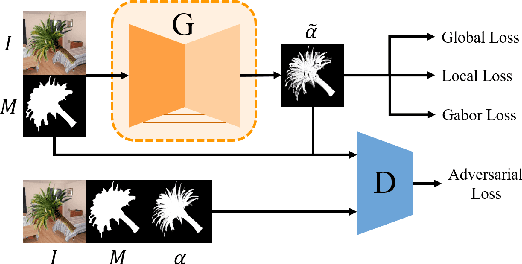
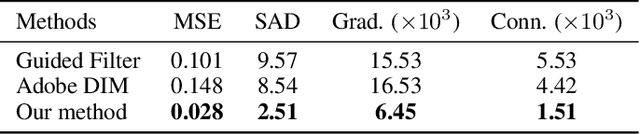
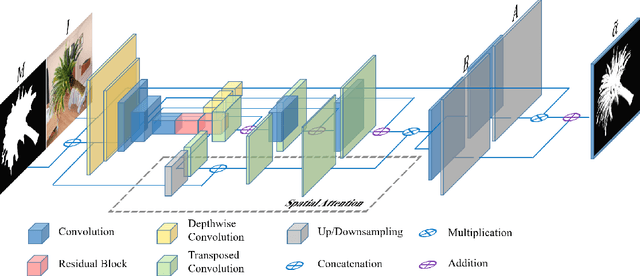
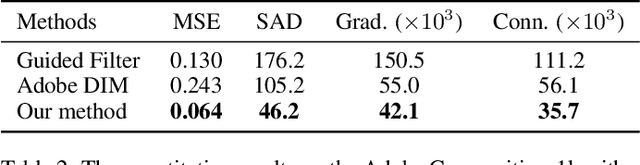
Recently, significant progress has been achieved in deep image matting. Most of the classical image matting methods are time-consuming and require an ideal trimap which is difficult to attain in practice. A high efficient image matting method based on a weakly annotated mask is in demand for mobile applications. In this paper, we propose a novel method based on Deep Learning and Guided Filter, called Inductive Guided Filter, which can tackle the real-time general image matting task on mobile devices. We design a lightweight hourglass network to parameterize the original Guided Filter method that takes an image and a weakly annotated mask as input. Further, the use of Gabor loss is proposed for training networks for complicated textures in image matting. Moreover, we create an image matting dataset MAT-2793 with a variety of foreground objects. Experimental results demonstrate that our proposed method massively reduces running time with robust accuracy.
Multi-View Constraint Propagation with Consensus Prior Knowledge
Sep 21, 2016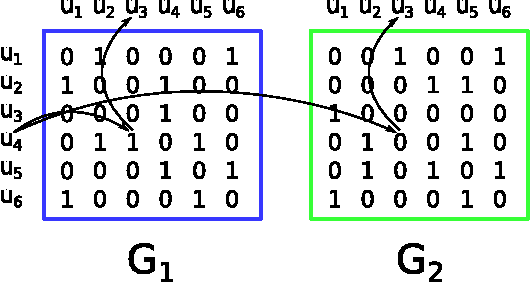
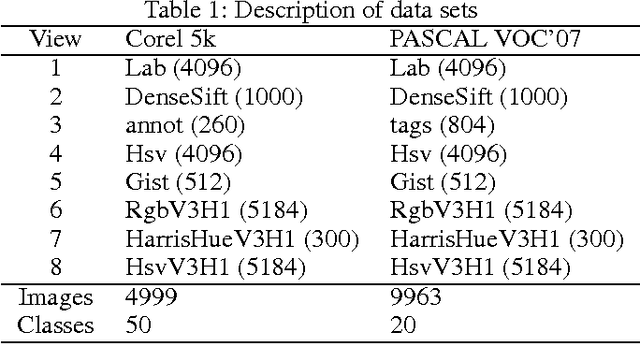
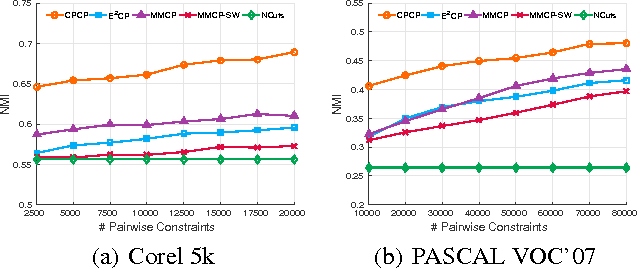
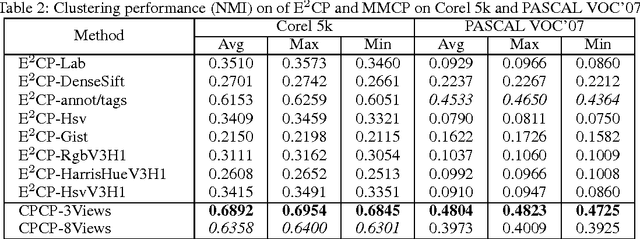
In many applications, the pairwise constraint is a kind of weaker supervisory information which can be collected easily. The constraint propagation has been proved to be a success of exploiting such side-information. In recent years, some methods of multi-view constraint propagation have been proposed. However, the problem of reasonably fusing different views remains unaddressed. In this paper, we present a method dubbed Consensus Prior Constraint Propagation (CPCP), which can provide the prior knowledge of the robustness of each data instance and its neighborhood. With the robustness generated from the consensus information of each view, we build a unified affinity matrix as a result of the propagation. Specifically, we fuse the affinity of different views at a data instance level instead of a view level. This paper also introduces an approach to deal with the imbalance between the positive and negative constraints. The proposed method has been tested in clustering tasks on two publicly available multi-view data sets to show the superior performance.
Adaptive Affinity Matrix for Unsupervised Metric Learning
Sep 11, 2016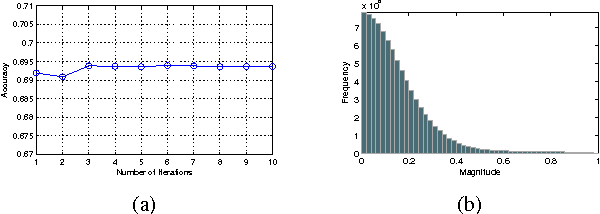

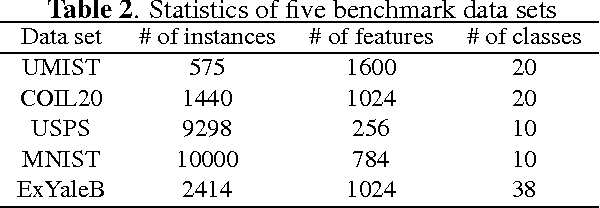
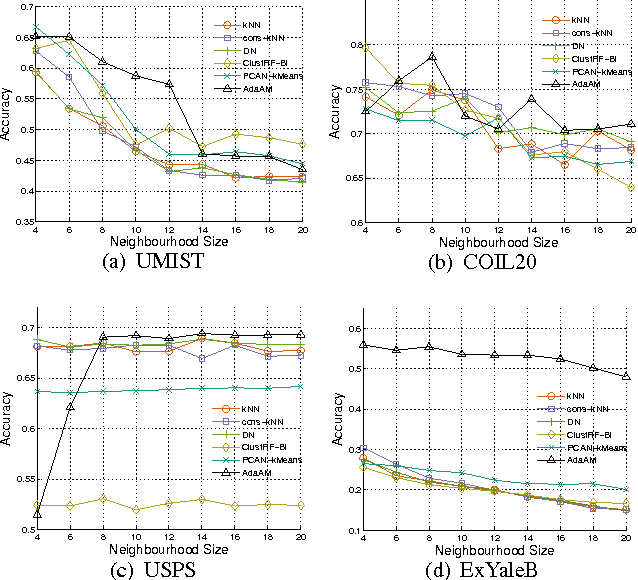
Spectral clustering is one of the most popular clustering approaches with the capability to handle some challenging clustering problems. Most spectral clustering methods provide a nonlinear map from the data manifold to a subspace. Only a little work focuses on the explicit linear map which can be viewed as the unsupervised distance metric learning. In practice, the selection of the affinity matrix exhibits a tremendous impact on the unsupervised learning. While much success of affinity learning has been achieved in recent years, some issues such as noise reduction remain to be addressed. In this paper, we propose a novel method, dubbed Adaptive Affinity Matrix (AdaAM), to learn an adaptive affinity matrix and derive a distance metric from the affinity. We assume the affinity matrix to be positive semidefinite with ability to quantify the pairwise dissimilarity. Our method is based on posing the optimization of objective function as a spectral decomposition problem. We yield the affinity from both the original data distribution and the widely-used heat kernel. The provided matrix can be regarded as the optimal representation of pairwise relationship on the manifold. Extensive experiments on a number of real-world data sets show the effectiveness and efficiency of AdaAM.