 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIE++: Towards End-to-End Information Extraction from Visually Rich Documents
Paper and Code

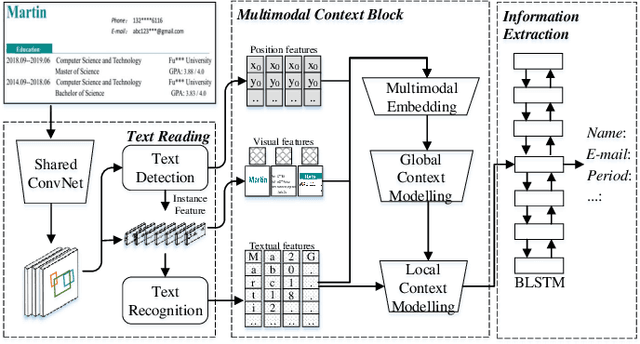
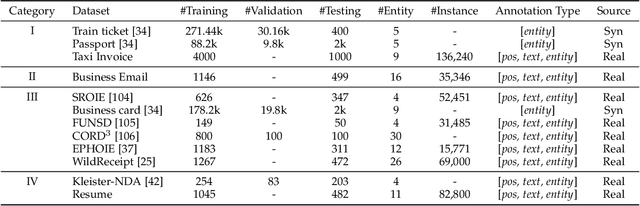
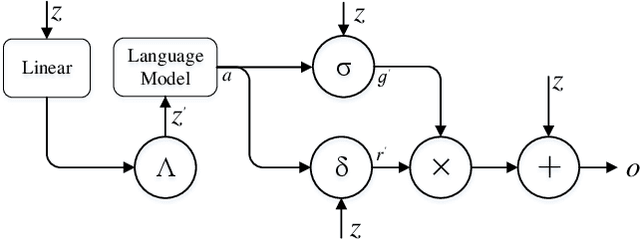
Recently, automatically extracting information from visually rich documents (e.g., tickets and resumes) has become a hot and vital research topic due to its widespread commercial value. Most existing methods divide this task into two subparts: the text reading part for obtaining the plain text from the original document images and the information extraction part for extracting key contents. These methods mainly focus on improving the second, while neglecting that the two parts are highly correlated. This paper proposes a unified end-to-end information extraction framework from visually rich documents, where text reading and information extraction can reinforce each other via a well-designed multi-modal context block. Specifically, the text reading part provides multi-modal features like visual, textual and layout features. The multi-modal context block is developed to fuse the generated multi-modal features and even the prior knowledge from the pre-trained language model for better semantic representation. The information extraction part is responsible for generating key contents with the fused context features. The framework can be trained in an end-to-end trainable manner, achieving global optimization. What is more, we define and group visually rich documents into four categories across two dimensions, the layout and text type. For each document category, we provide or recommend the corresponding benchmarks, experimental settings and strong baselines for remedying the problem that this research area lacks the uniform evaluation standard. Extensive experiments on four kinds of benchmarks (from fixed layout to variable layout, from full-structured text to semi-unstructured text) are reported, demonstrating the proposed method's effectiveness. Data, source code and models are available.