 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Law for Post-training after Model Pruning
Paper and Code
Nov 15, 2024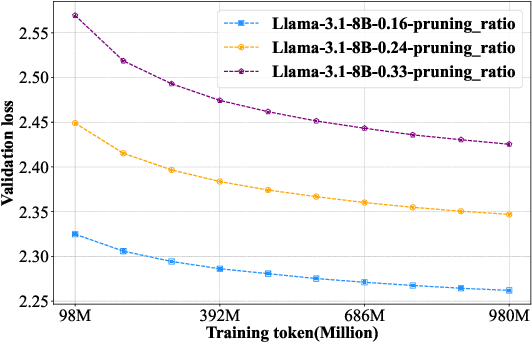
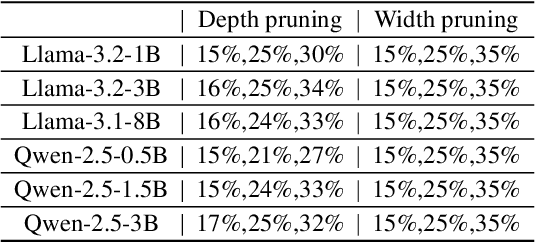
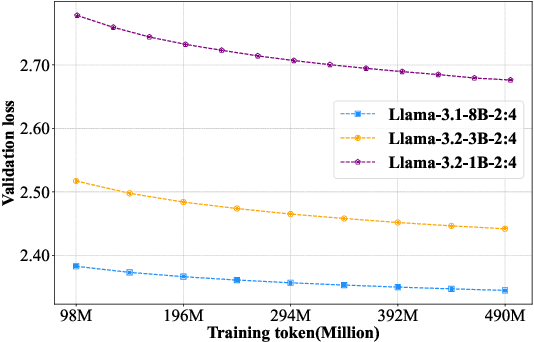
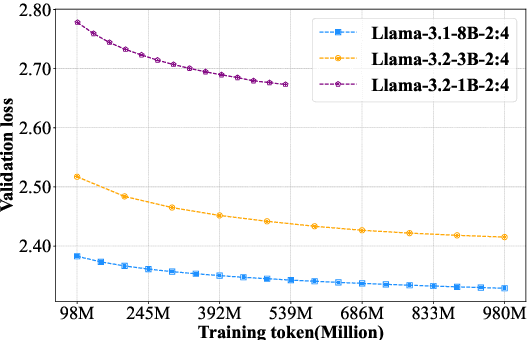
Large language models (LLMs) based on the Transformer architecture are widely employed across various domains and tasks. However, their increasing size imposes significant hardware demands, limiting practical deployment. To mitigate this, model pruning techniques have been developed to create more efficient models while maintaining high performance. Despite this, post-training after pruning is crucial for performance recovery and can be resource-intensive. This paper investigates the post-training requirements of pruned LLMs and introduces a scaling law to determine the optimal amount of post-training data. Post-training experiments with the Llama-3 and Qwen-2.5 series models, pruned using depth pruning, width pruning, and 2:4 semi-structured pruning, show that higher pruning ratios necessitate more post-training data for performance recovery, whereas larger LLMs require less. The proposed scaling law predicts a model's loss based on its parameter counts before and after pruning, as well as the post-training token counts. Furthermore, we find that the scaling law established from smaller LLMs can be reliably extrapolated to larger LLMs. This work provides valuable insights into the post-training of pruned LLMs and offers a practical scaling law for optimizing post-training data usage.