 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards VM Rescheduling Optimization Through Deep Reinforcement Learning
May 23, 2025Modern industry-scale data centers need to manage a large number of virtual machines (VMs). Due to the continual creation and release of VMs, many small resource fragments are scattered across physical machines (PMs). To handle these fragments, data centers periodically reschedule some VMs to alternative PMs, a practice commonly referred to as VM rescheduling. Despite the increasing importance of VM rescheduling as data centers grow in size, the problem remains understudied. We first show that, unlike most combinatorial optimization tasks, the inference time of VM rescheduling algorithms significantly influences their performance, due to dynamic VM state changes during this period. This causes existing methods to scale poorly. Therefore, we develop a reinforcement learning system for VM rescheduling, VM2RL, which incorporates a set of customized techniques, such as a two-stage framework that accommodates diverse constraints and workload conditions, a feature extraction module that captures relational information specific to rescheduling, as well as a risk-seeking evaluation enabling users to optimize the trade-off between latency and accuracy. We conduct extensive experiments with data from an industry-scale data center. Our results show that VM2RL can achieve a performance comparable to the optimal solution but with a running time of seconds. Code and datasets are open-sourced: https://github.com/zhykoties/VMR2L_eurosys, https://drive.google.com/drive/folders/1PfRo1cVwuhH30XhsE2Np3xqJn2GpX5qy.
Golden-Retriever: High-Fidelity Agentic Retrieval Augmented Generation for Industrial Knowledge Base
Jul 20, 2024This paper introduces Golden-Retriever, designed to efficiently navigate vast industrial knowledge bases, overcoming challenges in traditional LLM fine-tuning and RAG frameworks with domain-specific jargon and context interpretation. Golden-Retriever incorporates a reflection-based question augmentation step before document retrieval, which involves identifying jargon, clarifying its meaning based on context, and augmenting the question accordingly. Specifically, our method extracts and lists all jargon and abbreviations in the input question, determines the context against a pre-defined list, and queries a jargon dictionary for extended definitions and descriptions. This comprehensive augmentation ensures the RAG framework retrieves the most relevant documents by providing clear context and resolving ambiguities, significantly improving retrieval accuracy. Evaluations using three open-source LLMs on a domain-specific question-answer dataset demonstrate Golden-Retriever's superior performance, providing a robust solution for efficiently integrating and querying industrial knowledge bases.
Go Beyond Black-box Policies: Rethinking the Design of Learning Agent for Interpretable and Verifiable HVAC Control
Feb 29, 2024Recent research has shown the potential of Model-based Reinforcement Learning (MBRL) to enhance energy efficiency of Heating, Ventilation, and Air Conditioning (HVAC) systems. However, existing methods rely on black-box thermal dynamics models and stochastic optimizers, lacking reliability guarantees and posing risks to occupant health. In this work, we overcome the reliability bottleneck by redesigning HVAC controllers using decision trees extracted from existing thermal dynamics models and historical data. Our decision tree-based policies are deterministic, verifiable, interpretable, and more energy-efficient than current MBRL methods. First, we introduce a novel verification criterion for RL agents in HVAC control based on domain knowledge. Second, we develop a policy extraction procedure that produces a verifiable decision tree policy. We found that the high dimensionality of the thermal dynamics model input hinders the efficiency of policy extraction. To tackle the dimensionality challenge, we leverage importance sampling conditioned on historical data distributions, significantly improving policy extraction efficiency. Lastly, we present an offline verification algorithm that guarantees the reliability of a control policy. Extensive experiments show that our method saves 68.4% more energy and increases human comfort gain by 14.8% compared to the state-of-the-art method, in addition to an 1127x reduction in computation overhead. Our code and data are available at https://github.com/ryeii/Veri_HVAC
Reward Bound for Behavioral Guarantee of Model-based Planning Agents
Feb 20, 2024Recent years have seen an emerging interest in the trustworthiness of machine learning-based agents in the wild, especially in robotics, to provide safety assurance for the industry. Obtaining behavioral guarantees for these agents remains an important problem. In this work, we focus on guaranteeing a model-based planning agent reaches a goal state within a specific future time step. We show that there exists a lower bound for the reward at the goal state, such that if the said reward is below that bound, it is impossible to obtain such a guarantee. By extension, we show how to enforce preferences over multiple goals.
Data Race Detection Using Large Language Models
Aug 15, 2023



Large language models (LLMs) are demonstrating significant promise as an alternate strategy to facilitate analyses and optimizations of high-performance computing programs, circumventing the need for resource-intensive manual tool creation. In this paper, we explore a novel LLM-based data race detection approach combining prompting engineering and fine-tuning techniques. We create a dedicated dataset named DRB-ML, which is derived from DataRaceBench, with fine-grain labels showing the presence of data race pairs and their associated variables, line numbers, and read/write information. DRB-ML is then used to evaluate representative LLMs and fine-tune open-source ones. Our experiment shows that LLMs can be a viable approach to data race detection. However, they still cannot compete with traditional data race detection tools when we need detailed information about variable pairs causing data races.
Optimizing Irrigation Efficiency using Deep Reinforcement Learning in the Field
Apr 04, 2023Agricultural irrigation is a significant contributor to freshwater consumption. However, the current irrigation systems used in the field are not efficient. They rely mainly on soil moisture sensors and the experience of growers, but do not account for future soil moisture loss. Predicting soil moisture loss is challenging because it is influenced by numerous factors, including soil texture, weather conditions, and plant characteristics. This paper proposes a solution to improve irrigation efficiency, which is called DRLIC. DRLIC is a sophisticated irrigation system that uses deep reinforcement learning (DRL) to optimize its performance. The system employs a neural network, known as the DRL control agent, which learns an optimal control policy that considers both the current soil moisture measurement and the future soil moisture loss. We introduce an irrigation reward function that enables our control agent to learn from previous experiences. However, there may be instances where the output of our DRL control agent is unsafe, such as irrigating too much or too little water. To avoid damaging the health of the plants, we implement a safety mechanism that employs a soil moisture predictor to estimate the performance of each action. If the predicted outcome is deemed unsafe, we perform a relatively-conservative action instead. To demonstrate the real-world application of our approach, we developed an irrigation system that comprises sprinklers, sensing and control nodes, and a wireless network. We evaluate the performance of DRLIC by deploying it in a testbed consisting of six almond trees. During a 15-day in-field experiment, we compared the water consumption of DRLIC with a widely-used irrigation scheme. Our results indicate that DRLIC outperformed the traditional irrigation method by achieving a water savings of up to 9.52%.
Exploring Deep Reinforcement Learning for Holistic Smart Building Control
Jan 27, 2023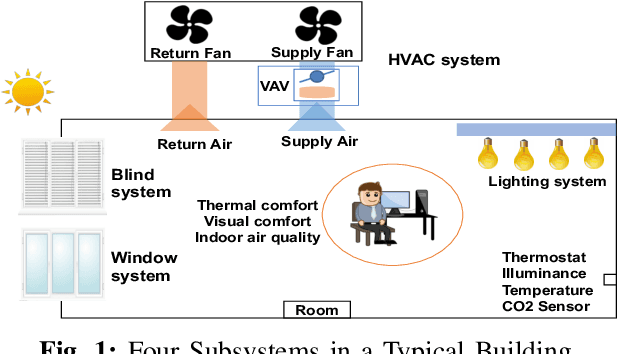
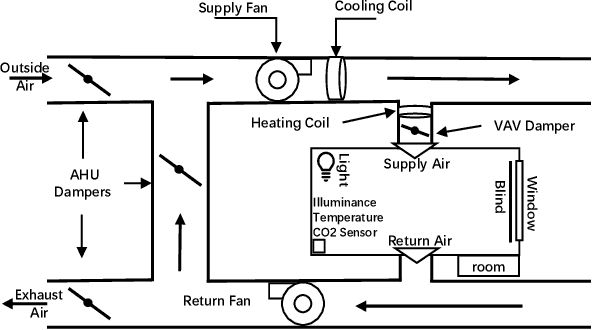
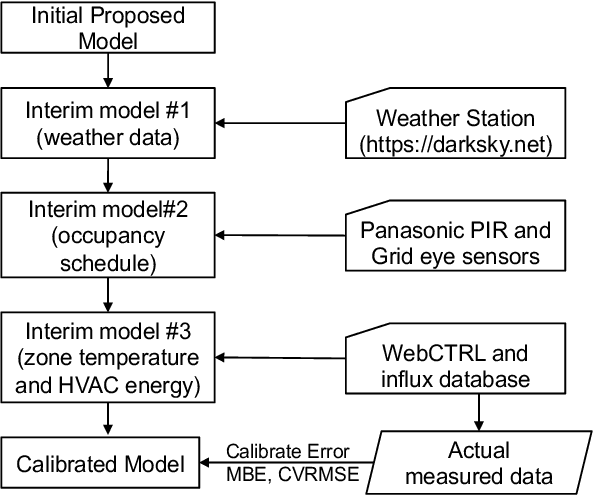

In this paper, we take a holistic approach to deal with the tradeoffs between energy use and comfort in commercial buildings. We developed a system called OCTOPUS, which employs a novel deep reinforcement learning (DRL) framework that uses a data-driven approach to find the optimal control sequences of all building's subsystems, including HVAC, lighting, blind and window systems. The DRL architecture includes a novel reward function that allows the framework to explore the tradeoffs between energy use and users' comfort, while at the same time enabling the solution of the high-dimensional control problem due to the interactions of four different building subsystems. In order to cope with OCTOPUS's data training requirements, we argue that calibrated simulations that match the target building operational points are the vehicle to generate enough data to be able to train our DRL framework to find the control solution for the target building. In our work, we trained OCTOPUS with 10-year weather data and a building model that is implemented in the EnergyPlus building simulator, which was calibrated using data from a real production building. Through extensive simulations, we demonstrate that OCTOPUS can achieve 14.26% and 8.1% energy savings compared with the state-of-the-art rule-based method in a LEED Gold Certified building and the latest DRL-based method available in the literature respectively, while maintaining human comfort within a desired range.