 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe HCCL Speaker Verification System for Far-Field Speaker Verification Challenge
Paper and Code
Jul 03, 2021


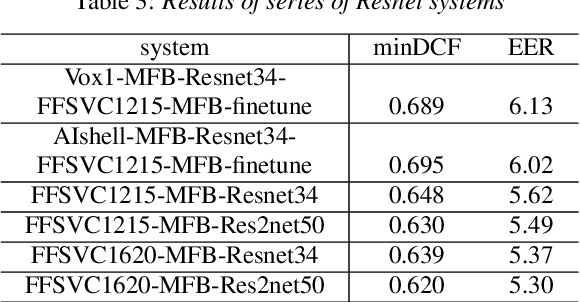
This paper describes the systems submitted by team HCCL to the Far-Field Speaker Verification Challenge. Our previous work in the AIshell Speaker Verification Challenge 2019 shows that the powerful modeling abilities of Neural Network architectures can provide exceptional performance for this kind of task. Therefore, in this challenge, we focus on constructing deep Neural Network architectures based on TDNN, Resnet and Res2net blocks. Most of the developed systems consist of Neural Network embeddings are applied with PLDA backend. Firstly, the speed perturbation method is applied to augment data and significant performance improvements are achieved. Then, we explore the use of AMsoftmax loss function and propose to join a CE-loss branch when we train model using AMsoftmax loss. In addition, the impact of score normalization on performance is also investigated. The final system, a fusion of four systems, achieves minDCF 0.5342, EER 5.05\% on task1 eval set, and achieves minDCF 0.5193, EER 5.47\% on task3 eval set.