 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReminding the Incremental Language Model via Data-Free Self-Distillation
Paper and Code
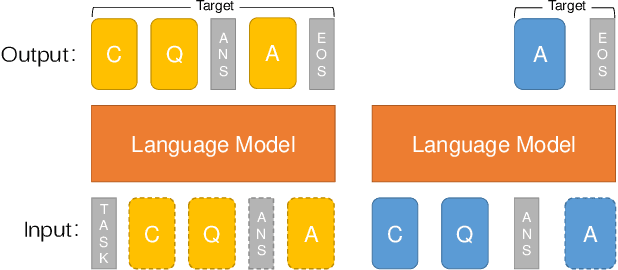
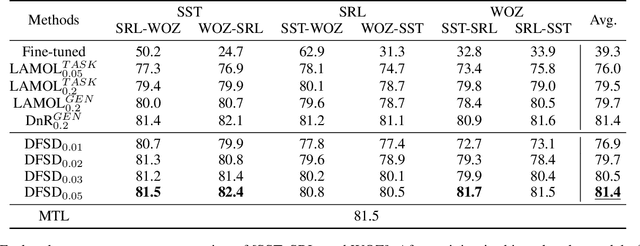
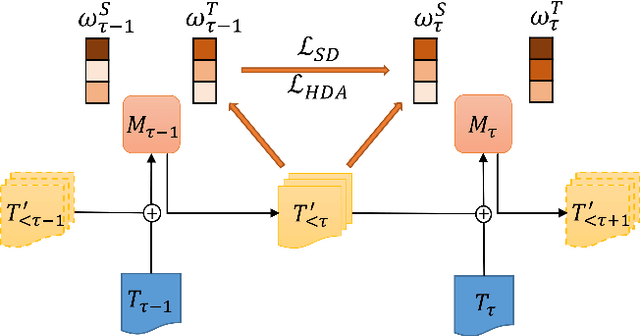

Incremental language learning with pseudo-data can alleviate catastrophic forgetting in neural networks. However, to obtain better performance, former methods have higher demands for pseudo-data of the previous tasks. The performance dramatically decreases when fewer pseudo-data are employed. In addition, the distribution of pseudo-data gradually deviates from the real data with the sequential learning of different tasks. The deviation will be greater with more tasks learned, which results in more serious catastrophic forgetting. To address these issues, we propose reminding incremental language model via data-free self-distillation (DFSD), which includes self-distillation based on the Earth Mover's Distance and hidden data augmentation. By estimating the knowledge distribution in all layers of GPT-2 and transforming it from teacher model to student model, the Self-distillation based on the Earth Mover's Distance can significantly reduce the demand for pseudo-data. Hidden data augmentation can greatly alleviate the catastrophic forgetting caused by deviations via modeling the generation of pseudo-data as a hidden data augmentation process, where each sample is a mixture of all trained task data. The experimental results demonstrate that our DFSD can exceed the previous state-of-the-art methods even if the maximum decrease in pseudo-data is 90%.