 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogDevelop2K: Reversed Cognitive Development in Multimodal Large Language Models
Paper and Code
Oct 06, 2024
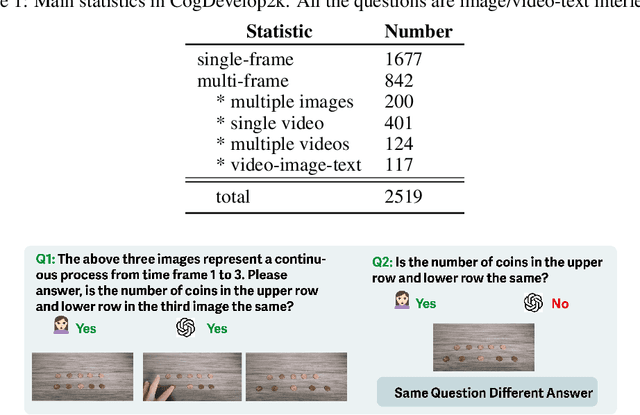


Are Multi-modal Large Language Models (MLLMs) stochastic parrots? Do they genuinely understand and are capable of performing the tasks they excel at? This paper aims to explore the fundamental basis of MLLMs, i.e. core cognitive abilities that human intelligence builds upon to perceive, comprehend, and reason. To this end, we propose CogDevelop2K, a comprehensive benchmark that spans 12 sub-concepts from fundamental knowledge like object permanence and boundary to advanced reasoning like intentionality understanding, structured via the developmental trajectory of a human mind. We evaluate 46 MLLMs on our benchmarks. Comprehensively, we further evaluate the influence of evaluation strategies and prompting techniques. Surprisingly, we observe a reversed cognitive developmental trajectory compared to humans.