 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Graph Neural Networks: A Mutual Learning Approach
Oct 22, 2025Knowledge distillation (KD) techniques have emerged as a powerful tool for transferring expertise from complex teacher models to lightweight student models, particularly beneficial for deploying high-performance models in resource-constrained devices. This approach has been successfully applied to graph neural networks (GNNs), harnessing their expressive capabilities to generate node embeddings that capture structural and feature-related information. In this study, we depart from the conventional KD approach by exploring the potential of collaborative learning among GNNs. In the absence of a pre-trained teacher model, we show that relatively simple and shallow GNN architectures can synergetically learn efficient models capable of performing better during inference, particularly in tackling multiple tasks. We propose a collaborative learning framework where ensembles of student GNNs mutually teach each other throughout the training process. We introduce an adaptive logit weighting unit to facilitate efficient knowledge exchange among models and an entropy enhancement technique to improve mutual learning. These components dynamically empower the models to adapt their learning strategies during training, optimizing their performance for downstream tasks. Extensive experiments conducted on three datasets each for node and graph classification demonstrate the effectiveness of our approach.
FedVLM: Scalable Personalized Vision-Language Models through Federated Learning
Jul 23, 2025Vision-language models (VLMs) demonstrate impressive zero-shot and few-shot learning capabilities, making them essential for several downstream tasks. However, fine-tuning these models at scale remains challenging, particularly in federated environments where data is decentralized and non-iid across clients. Existing parameter-efficient tuning methods like LoRA (Low-Rank Adaptation) reduce computational overhead but struggle with heterogeneous client data, leading to suboptimal generalization. To address these challenges, we propose FedVLM, a federated LoRA fine-tuning framework that enables decentralized adaptation of VLMs while preserving model privacy and reducing reliance on centralized training. To further tackle data heterogeneity, we introduce personalized LoRA (pLoRA), which dynamically adapts LoRA parameters to each client's unique data distribution, significantly improving local adaptation while maintaining global model aggregation. Experiments on the RLAIF-V dataset show that pLoRA improves client-specific performance by 24.5% over standard LoRA, demonstrating superior adaptation in non-iid settings. FedVLM provides a scalable and efficient solution for fine-tuning VLMs in federated settings, advancing personalized adaptation in distributed learning scenarios.
Tensor Train Low-rank Approximation (TT-LoRA): Democratizing AI with Accelerated LLMs
Aug 02, 2024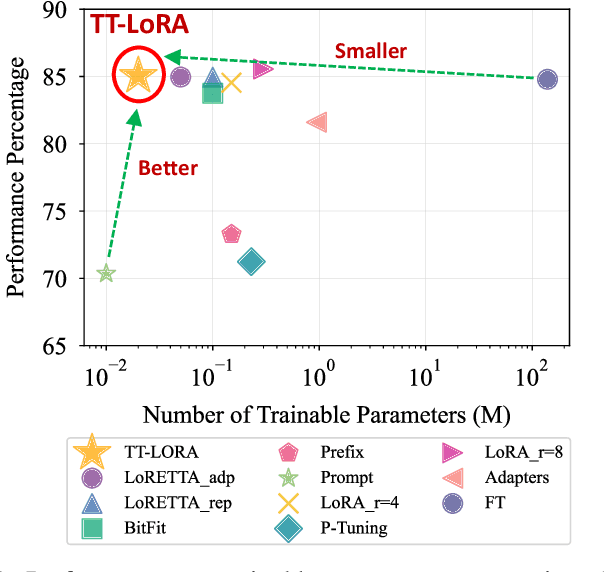
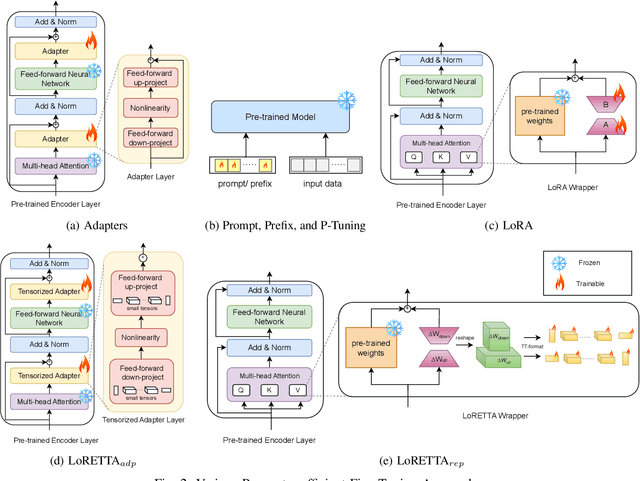
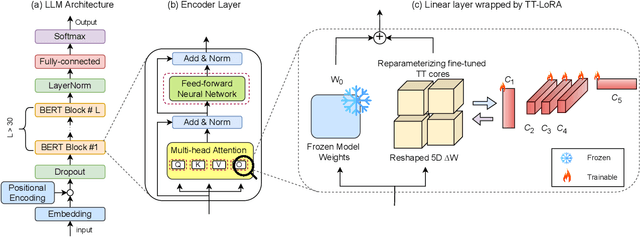
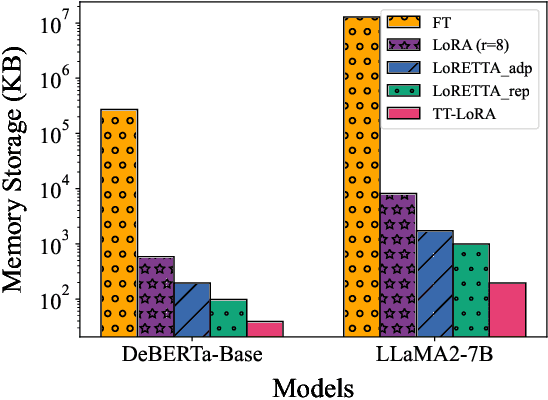
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing (NLP) tasks, such as question-answering, sentiment analysis, text summarization, and machine translation. However, the ever-growing complexity of LLMs demands immense computational resources, hindering the broader research and application of these models. To address this, various parameter-efficient fine-tuning strategies, such as Low-Rank Approximation (LoRA) and Adapters, have been developed. Despite their potential, these methods often face limitations in compressibility. Specifically, LoRA struggles to scale effectively with the increasing number of trainable parameters in modern large scale LLMs. Additionally, Low-Rank Economic Tensor-Train Adaptation (LoRETTA), which utilizes tensor train decomposition, has not yet achieved the level of compression necessary for fine-tuning very large scale models with limited resources. This paper introduces Tensor Train Low-Rank Approximation (TT-LoRA), a novel parameter-efficient fine-tuning (PEFT) approach that extends LoRETTA with optimized tensor train (TT) decomposition integration. By eliminating Adapters and traditional LoRA-based structures, TT-LoRA achieves greater model compression without compromising downstream task performance, along with reduced inference latency and computational overhead. We conduct an exhaustive parameter search to establish benchmarks that highlight the trade-off between model compression and performance. Our results demonstrate significant compression of LLMs while maintaining comparable performance to larger models, facilitating their deployment on resource-constraint platforms.