 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNERO: Explainable Out-of-Distribution Detection with Neuron-level Relevance
Jun 18, 2025

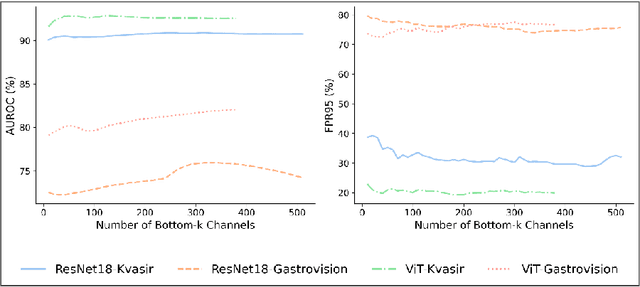

Ensuring reliability is paramount in deep learning, particularly within the domain of medical imaging, where diagnostic decisions often hinge on model outputs. The capacity to separate out-of-distribution (OOD) samples has proven to be a valuable indicator of a model's reliability in research. In medical imaging, this is especially critical, as identifying OOD inputs can help flag potential anomalies that might otherwise go undetected. While many OOD detection methods rely on feature or logit space representations, recent works suggest these approaches may not fully capture OOD diversity. To address this, we propose a novel OOD scoring mechanism, called NERO, that leverages neuron-level relevance at the feature layer. Specifically, we cluster neuron-level relevance for each in-distribution (ID) class to form representative centroids and introduce a relevance distance metric to quantify a new sample's deviation from these centroids, enhancing OOD separability. Additionally, we refine performance by incorporating scaled relevance in the bias term and combining feature norms. Our framework also enables explainable OOD detection. We validate its effectiveness across multiple deep learning architectures on the gastrointestinal imaging benchmarks Kvasir and GastroVision, achieving improvements over state-of-the-art OOD detection methods.
High Resolution Image Quality Database
Jan 29, 2024With technology for digital photography and high resolution displays rapidly evolving and gaining popularity, there is a growing demand for blind image quality assessment (BIQA) models for high resolution images. Unfortunately, the publicly available large scale image quality databases used for training BIQA models contain mostly low or general resolution images. Since image resizing affects image quality, we assume that the accuracy of BIQA models trained on low resolution images would not be optimal for high resolution images. Therefore, we created a new high resolution image quality database (HRIQ), consisting of 1120 images with resolution of 2880x2160 pixels. We conducted a subjective study to collect the subjective quality ratings for HRIQ in a controlled laboratory setting, resulting in accurate MOS at high resolution. To demonstrate the importance of a high resolution image quality database for training BIQA models to predict mean opinion scores (MOS) of high resolution images accurately, we trained and tested several traditional and deep learning based BIQA methods on different resolution versions of our database. The database is publicly available in https://github.com/jarikorhonen/hriq.
No-Reference Point Cloud Quality Assessment via Weighted Patch Quality Prediction
May 13, 2023



With the rapid development of 3D vision applications based on point clouds, point cloud quality assessment(PCQA) is becoming an important research topic. However, the prior PCQA methods ignore the effect of local quality variance across different areas of the point cloud. To take an advantage of the quality distribution imbalance, we propose a no-reference point cloud quality assessment (NR-PCQA) method with local area correlation analysis capability, denoted as COPP-Net. More specifically, we split a point cloud into patches, generate texture and structure features for each patch, and fuse them into patch features to predict patch quality. Then, we gather the features of all the patches of a point cloud for correlation analysis, to obtain the correlation weights. Finally, the predicted qualities and correlation weights for all the patches are used to derive the final quality score. Experimental results show that our method outperforms the state-of-the-art benchmark NR-PCQA methods. The source code for the proposed COPP-Net can be found at https://github.com/philox12358/COPP-Net.
Half of an image is enough for quality assessment
Feb 09, 2023Deep networks have demonstrated promising results in the field of Image Quality Assessment (IQA). However, there has been limited research on understanding how deep models in IQA work. This study introduces a novel positional masked transformer for IQA and provides insights into the contribution of different regions of an image towards its overall quality. Results indicate that half of an image may play a trivial role in determining image quality, while the other half is critical. This observation is extended to several other CNN-based IQA models, revealing that half of the image regions can significantly impact the overall image quality. To further enhance our understanding, three semantic measures (saliency, frequency, and objectness) were derived and found to have high correlation with the importance of image regions in IQA.
Consumer Image Quality Prediction using Recurrent Neural Networks for Spatial Pooling
Jun 02, 2021
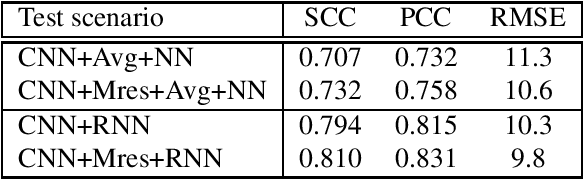


Promising results for subjective image quality prediction have been achieved during the past few years by using convolutional neural networks (CNN). However, the use of CNNs for high resolution image quality assessment remains a challenge, since typical CNN architectures have been designed for small resolution input images. In this study, we propose an image quality model that attempts to mimic the attention mechanism of human visual system (HVS) by using a recurrent neural network (RNN) for spatial pooling of the features extracted from different spatial areas (patches) by a deep CNN-based feature extractor. The experimental study, conducted by using images with different resolutions from two recently published image quality datasets, indicates that the quality prediction accuracy of the proposed method is competitive against benchmark models representing the state-of-the-art, and the proposed method also performs consistently on different resolution versions of the same dataset.
Transformer for Image Quality Assessment
Jan 08, 2021

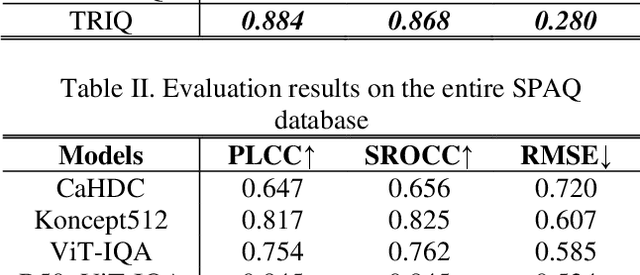

Transformer has become the new standard method in natural language processing (NLP), and it also attracts research interests in computer vision area. In this paper we investigate the application of Transformer in Image Quality (TRIQ) assessment. Following the original Transformer encoder employed in Vision Transformer (ViT), we propose an architecture of using a shallow Transformer encoder on the top of a feature map extracted by convolution neural networks (CNN). Adaptive positional embedding is employed in the Transformer encoder to handle images with arbitrary resolutions. Different settings of Transformer architectures have been investigated on publicly available image quality databases. We have found that the proposed TRIQ architecture achieves outstanding performance. The implementation of TRIQ is published on Github (https://github.com/junyongyou/triq).